在过去的几个月里,人工智能社区的知名人士对ChatGPT的下一次更新或GPT-5进行了广泛的猜测和警惕。许多人认为,这些更新可能会使我们更接近通用人工智能(AGI),甚至有人声称该模型可能具备博士级别的能力。
终于,就在今天早些时候,OpenAI宣布推出了一个名为OpenAI o1的新模型系列。虽然笔者尚未全面测试这个模型,但早期的评估和基准测试显示,它与GPT-4o有显著的不同,并有明显的改进。
这会是许多人期待的AGI吗?在我看来,我们还没有达到那个水平。然而,许多研究人员,包括现任和前任的OpenAI员工,都认为这可能是实现AGI的关键一步。
他们选择将其命名为 o1,这很耐人寻味。这暗示着这是一个新系列的开端,或许表明OpenAI将其视为迈向AGI之路的起点。
以下是你需要了解的关于 OpenAI o1 的 15 个事实与新特性。
1. 初始发布和目的
OpenAI宣布了o1模型,作为其AI开发的新篇章,重点关注复杂的推理任务。
它被特别设计用于在需要深度认知和问题解决的领域表现出色,如数学、科学和编程。
该模型的结构使其能够更深入地思考问题,区别于早期像GPT-4那样的快速、表面层次的响应。
2. 命名和模型设计
o1模型的发布标志着一个与以前模型不同的新系列的开始。OpenAI决定将模型计数重置为1,并将该系列命名为OpenAI o1,表明一个专注于推理能力的新时代的开启。
o1模型包括o1-Preview,一个全面的推理模型,以及o1-mini,一个更便宜、更快速的替代方案,特别适用于编码任务。
3. 初始能力
o1模型被设计为在复杂问题解决任务中优于以前的模型。
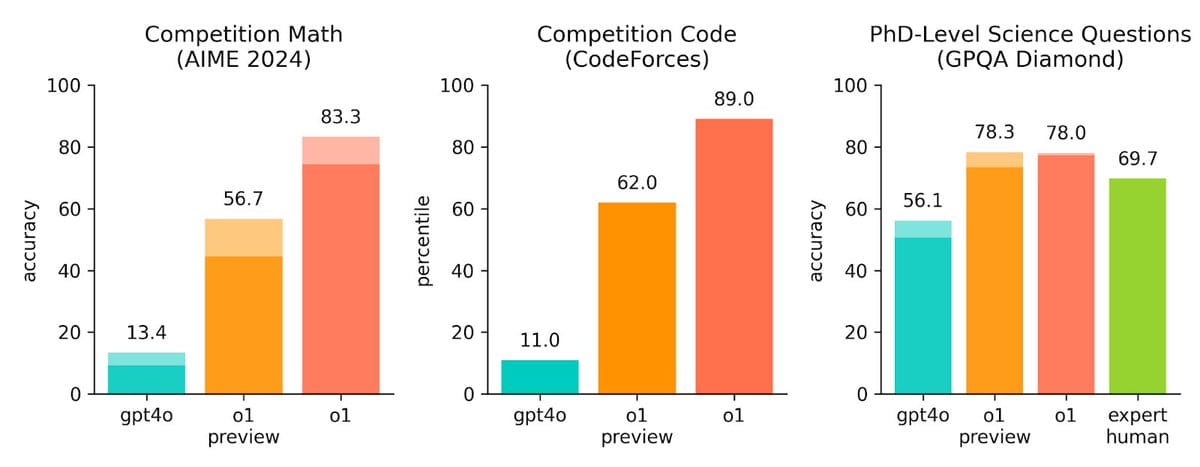
它展示了强大的能力,例如解决了83%的国际数学奥林匹克竞赛(IMO)问题,而GPT-4只解决了13%。
它还在科学和编码方面表现出色,在某些问题解决环境中与博士生相当。
4. 安全性和防破解能力
OpenAI在o1模型中高度重视安全性和一致性。通过新的训练技术,o1能够比以前的模型更有效地推理安全规则。
在测试中,o1对破解尝试表现出更高的抵抗力,在OpenAI最严格的安全测试中得分为84/100,而GPT-4的得分为22/100。
5. 可用性和访问权限
截至发布时,ChatGPT Plus和团队用户可以访问 o1-preview 和 o1-mini,预览版每周可发送30条消息,mini 版每周 50 条。
开发者也可以通过 OpenAI 的 API 使用该模型,但有速率限制。企业和教育用户将很快获得访问权限。
OpenAI 最终将把 o1-mini 版本提供给所有 ChatGPT 免费用户。
6. 推理改进和思维链
通过整合“思维链”推理,该模型学会了逐步解决问题。这种方法大大提高了o1的推理准确性,使其在需要逻辑步骤的领域更加有效。
7. 在竞赛编程和数学中的表现
o1模型在Codeforces中排名第89百分位,在美国数学奥林匹克竞赛(AIME)中进入前500名。它在需要大量推理的任务中表现出色,超越了GPT-4在数学方面的表现,在2024年AIME中得分为74%,而GPT-4仅为12%。
8. 强化学习和效率
该模型对其思维链使用了大规模的强化学习,随着训练时间的增加,其性能得到了提高。它有效地学会了思考并纠正错误,增强了整体推理能力。
9. 编程和奥赛的成功
在2024年的国际信息学奥林匹克竞赛(IOI)中,o1通过解决复杂的编程问题,排名在第49百分位。在竞赛编程评估中,它获得了1807的Elo评分,超过了93%的人类竞争者。
10. 科学和数学领域的人类水平
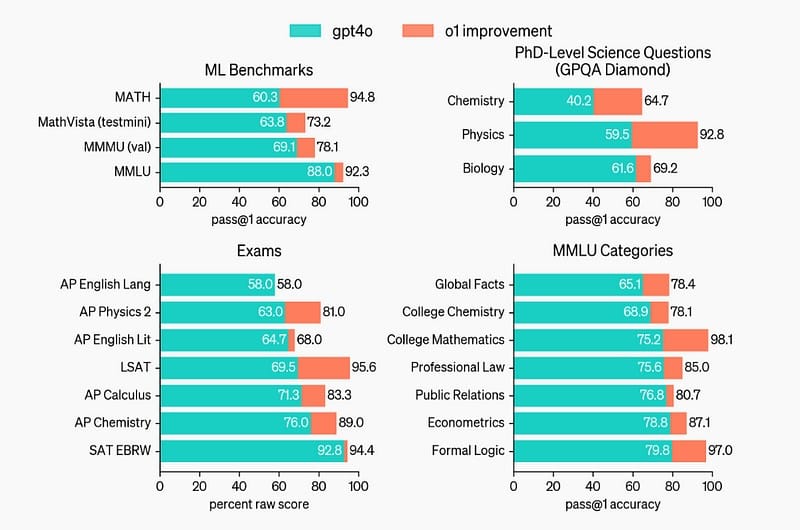
o1模型在化学、物理和生物学等领域超越了人类专家,成为第一个在GPQA-diamond基准测试中达到这一水平的模型。它在MMLU的57个子类别中有54个得分高于以前的模型。
11. 人类偏好
在直接对比的评估中,人类评估者在数据分析、编码和数学等领域始终更喜欢o1的回答,尽管GPT-4在某些自然语言任务中表现更佳。
12. 安全性和政策整合
“思维链”推理还通过允许模型在上下文中学习安全规则和人类价值观,改进了模型的一致性。这一进步使模型更具稳健性,特别是在超出训练分布的情境中。
13. 高级安全完成率
o1在有害提示类别中显著提高了安全完成率,在挑战性的破解中实现了93.4%的安全完成率,并在暴力不法行为、色情内容和有害行为建议等关键安全指标上优于GPT-4。
14. 隐藏的思维链监控
OpenAI选择对用户隐藏思维链,以防止任何潜在的操纵行为。然而,它利用这个隐藏的思维链来监控和提高模型的安全性,同时仍然为用户提供模型生成的摘要。
15. 未来发展和功能
虽然o1是一个强大的推理任务模型,但目前缺乏网页浏览、文件上传和图像识别等功能,而这些功能在GPT-4等模型中仍然可用。
OpenAI已承诺在未来的更新中添加这些功能,使o1模型在更广泛的任务中更加多才多艺。此外,预计o1系列和其他模型将有进一步的发展。
结语
因此,OpenAI o1 目前可能并不像 GPT4o 那样全能,它不能浏览网页或附加文件。但它在回答复杂任务方面具有更强的能力。
我认为我们回到了起点,但这次我们终于走上了正确的道路,去实现我们曾只在科幻电影中看到的东西。
我们还未完全达到目标,但看到它能如此迅速地改进,并能自行纠正错误,确实是一个令人印象深刻的创造。
最后,为了更好的使用 o1 模型,如何进行提问,OpenAI 给出的最佳方法:
- 保持提示简单直接:模型擅长理解和响应简短、清晰的指令,而不需要大量的指导。
- 避免思路链提示:由于这些模型在内部进行推理,因此不需要提示它们“逐步思考”或“解释你的推理”。
- 使用分隔符来提高清晰度: 使用三重引号、XML 标签或章节标题等分隔符来清楚地指示输入的不同部分,帮助模型适当地解释不同的部分。
- 限制检索增强生成 (RAG) 中的附加上下文: 提供附加上下文或文档时,仅包含最相关的信息,以防止模型过度复杂化其响应。


