微调(fine-tune) GPT-4o mini 模型对于那些希望定制 AI 应用程序的企业和开发者来说,无疑具有巨大的潜力。作为一个先进且经济高效的模型,GPT-4o mini在处理文本智能任务时表现出色,因此非常适合进行定制化微调。
通过对该模型进行微调,您可以提升其性能,使其更好地适应特定的用例,比如改进客户互动、生成更准确的响应,以及开发专门的功能。本文将引导您完成 GPT-4o mini 模型的微调并在应用中使用该模型,确保您能够最大限度地利用其能力来满足您的独特需求。
为什么选择GPT-4o mini?
GPT-4o mini是一款紧凑的AI语言模型,作为较大且资源密集型模型的替代品而开发。它旨在在性能与成本效益之间取得平衡,特别适合那些需要AI能力但预算或计算资源有限的开发者和企业。
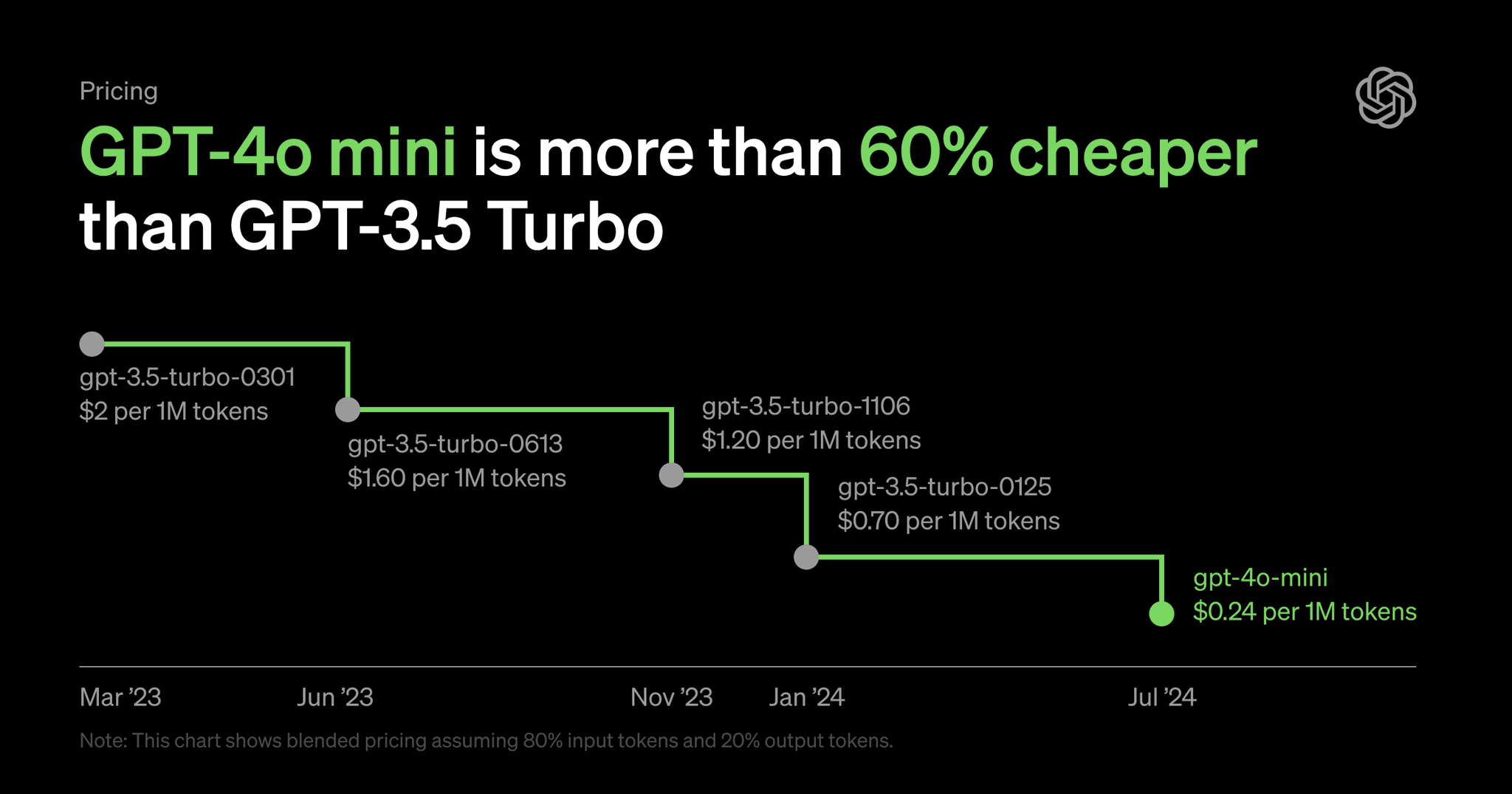
- 成本考虑:与较大的模型相比,GPT-4o mini的计算成本可能较低。这使得它对于预算有限的企业和开发者来说是一个可行的选择,尽管具体的节省效果取决于特定的用例和实现。在数字上,GPT-4o mini比原始GPT-4便宜66倍,比GPT-4o便宜33倍。
- 性能:虽然比一些替代方案小,但GPT-4o mini在常见的语言任务上表现得足够好。它在自然语言处理和功能调用等领域的能力应根据具体项目要求进行评估。各种基准测试表明,GPT-4o mini的表现与原始GPT-4相当,这非常了不起。
- 适应性:像许多语言模型一样,GPT-4o mini可以针对特定应用进行微调。这使得它在某些特定用例中,可能会超越更大且更昂贵的模型。
微调GPT-4o mini的成本是多少?
在2024年9月23日之前,微调GPT-4o mini是免费的。在此日期之后,费用为每百万个训练标记3美元。使用微调后的GPT-4o模型也非常经济:
- 每百万个输入标记0.3美元
- 每百万个输出标记1.2美元
总的来说,微调LLM模型从未如此便宜。
微调GPT-4o mini的数据集格式
创建格式正确的高质量训练集对于成功的微调运行至关重要。训练数据的质量和相关性会显著影响微调后模型的性能。对于OpenAI API,数据必须格式化为JSONL(JSON Lines)格式。JSONL是一种基于文本的格式,每行代表一个独立的、有效的JSON对象。这种结构使得逐行处理大型数据集变得高效。
对于文本完成模型,JSONL的内容相对简单:您只需要提供提示/回答对(例如davinci-002)或带有“user”和“assistant”角色的消息数组(如OpenAI API请求负载中的chat模型)。
以下是文本完成模型的JSONL格式示例:
{"prompt": "Summarize the main points of the article:", "completion": "The article discusses..."}
{"prompt": "Translate the following sentence to French:", "completion": "La traduction est..."}
{"prompt": "What are the key features of Python?", "completion": "Python's key features include..."}
对于本指南,我们使用一个聊天模型,因此需要创建聊天模型格式。为了演示,我们将使用一个包含少量示例的小型数据集。数据由客户服务咨询和相应的回答组成。
以下是本指南中用于示范微调OpenAI聊天模型的示例数据:
{
"messages": [{"role": "system", "content": "You are a customer service representative for an online bookstore."},
{"role": "user", "content": "How long does shipping usually take?"},
{"role": "assistant", "content": "Shipping times typically range from 3-5 business days for standard delivery. Express shipping options are available for faster delivery."}]
}
{
"messages": [{"role": "system", "content": "You are a customer service representative for an online bookstore."},
{"role": "user", "content": "Can I return a book if I don't like it?"},
{"role": "assistant", "content": "Yes, we offer a 30-day return policy for books in new condition. Please keep the original receipt for your return."}]
}
记住,这只是一个用于演示的小数据集。在实际操作中,您需要更大、更多样化的示例集来有效地微调您的模型。
注意:这些示例已格式化为更易阅读的形式。对于实际数据集,请确保每个JSON字典都在一行上。
例如:
{ "messages": [{"role": "system", "content": "You are a customer service representative for an online bookstore."}, {"role": "user", "content": "Can I return a book if I don't like it?"}, {"role": "assistant", "content": "Yes, we offer a 30-day return policy for books in new condition. Please keep the original receipt for your return."}] }
另外,微调时至少需要 10 个示例。
微调LLM需要多少数据?
微调LLM所需的数据量可能因多种因素而异:
- 任务的复杂性:更复杂的任务通常需要更多的数据。
- 期望的性能水平:更高的性能期望通常需要更多的训练数据。
- 基础模型的大小和能力:更大的模型可能需要更多数据才能有效微调。
- 领域特异性:高度专业化的任务可能需要更多领域特定的示例。
一般指导:
- 最低要求:OpenAI建议至少有100个示例进行微调,但对于复杂任务,这通常不足。
- 典型范围:许多成功的微调项目使用500到10,000个示例。
- 上限:一些大规模项目可能会使用10万或更多的示例,尤其是对于多样化或复杂任务。
需要注意的是,质量往往比数量更重要。一个小规模的高质量、多样化的数据集有时比一个大规模的低质量或重复性数据集表现更好。此外,随着数据集规模的增加,持续评估模型的性能也很重要,因为在某些时候可能会出现收益递减的情况。
注意:这一点非常重要。在传统的机器学习时代,需要数百万行数据。然而,LLM不同,即使少量数据也能影响模型的输出。因此,确保没有(零)错误数据,并拥有适量但不庞大的高质量数据行是至关重要的。
为了获得最佳结果,建议从一个中等规模的高质量数据集开始,并在监控性能改进的同时逐步增加数据量。这种方法可以帮助您找到数据量与模型性能之间的最佳平衡点,以适应您的特定用例。
GPT-4o mini微调方法及步骤
1、访问OpenAI微调控制台
首先,导航到OpenAI的微调控制台。
2、创建微调任务
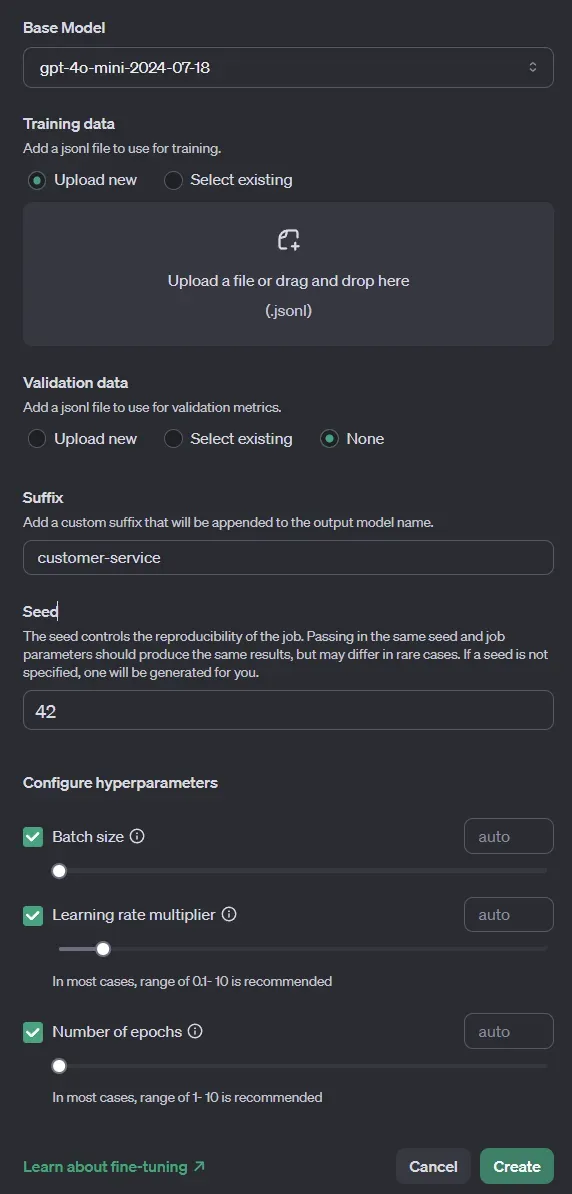
点击“Create”按钮。在弹出的窗口中进行以下设置:
- 选择基础模型为gpt-4o-mini。
- 训练数据:上传之前准备好的jsonl文件。
- 验证数据:选择“None”。如果您有单独的验证数据集,可以在此处上传,验证数据集的格式与训练数据集相同,用于在训练过程中和训练完成后评估模型性能。
- 后缀:为微调后的模型名称添加一个后缀,以便日后识别该特定模型。
- 种子:如果您希望结果具有可重复性,可以设置一个特定的种子。相同的种子和任务参数应产生一致的微调结果。
- 批量大小:首次运行时设置为自动。批量大小主要影响训练速度,对模型性能影响较小。由于训练是在OpenAI的基础设施上运行,保持自动设置是一个不错的选择。
- 学习率倍率:首次运行时也设置为自动。学习率倍率是一个超参数,控制训练过程中模型权重的更新幅度。较小的值可以防止过拟合,并可能稳定训练过程,但过小的值会减慢训练速度。一般来说,有较好的方法可以自动确定学习率,因此保持自动设置也是一个好选择。
3、开始微调
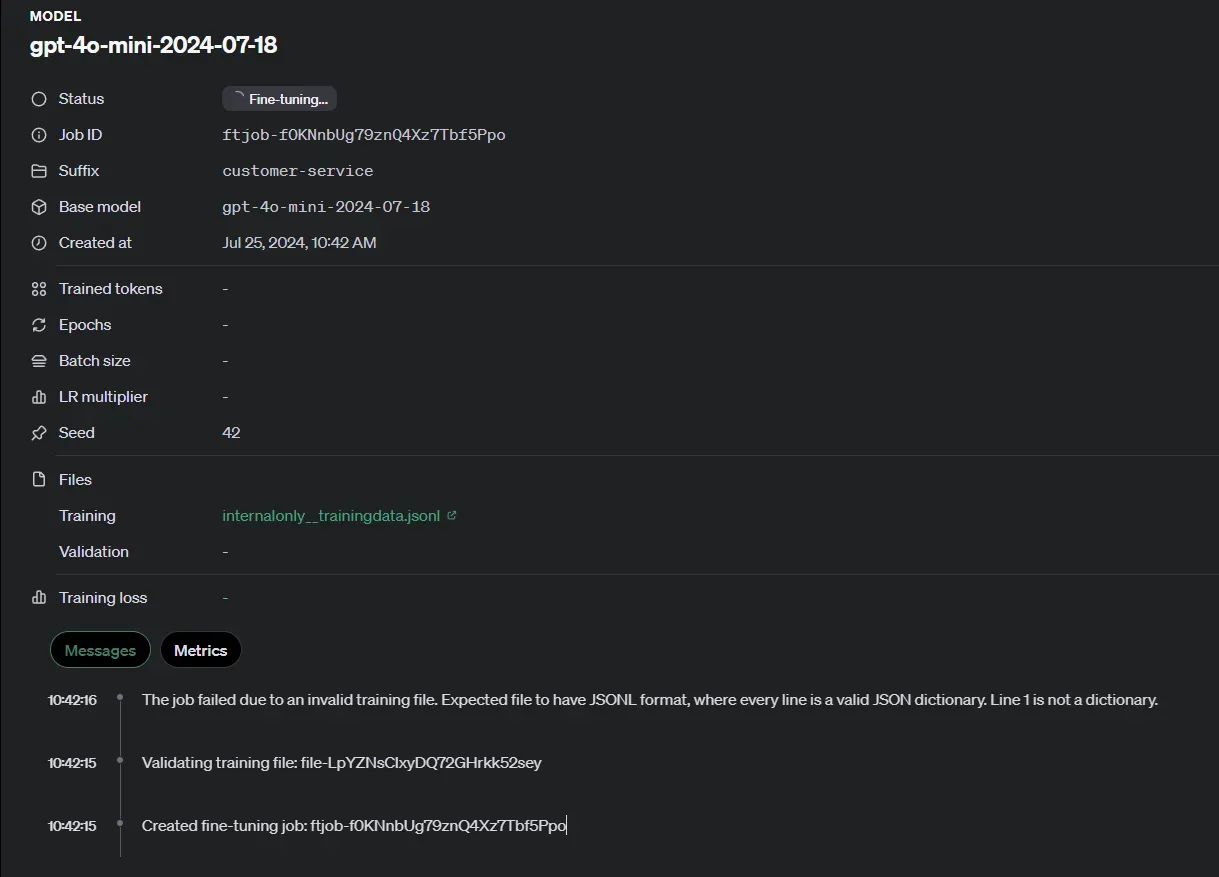
点击“Create”按钮,您将看到一个正在运行的任务及其当前阶段的摘要。
4、检查训练损失

任务完成后,您将看到模型训练过程的训练损失图表。一般来说,您希望训练损失随着训练过程的进行而下降并最终达到一个较低的稳定值。如果训练损失没有下降,您可能需要更多或不同的训练数据,或者调整学习率。
微调后的模型如何使用?
在任务完成后,您可以在任务页面顶部找到微调后的模型名称,例如:
ft:gpt-4o-mini-2024-07-18:russmedia-digital-gmbh:customer-service:9oofdDLO前往OpenAI Chat Playground,在左上角的下拉菜单中选择您的微调模型,然后使用聊天界面测试其功能。
如果您希望在自己的应用中使用该微调模型,可以通过以下代码来实现:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="ft:gpt-4o-mini-2024-07-18:russmedia-digital-gmbh:customer-service:9oofdDLO",
messages=[
{"role": "system", "content": "You are a customer service representative for an online bookstore. Provide helpful and friendly assistance to customers with their inquiries."},
{"role": "user", "content": "I received a damaged book. What should I do?"}
]
)
print(completion.choices[0].message.content)
微调与嵌入/检索增强生成的选择
嵌入与检索增强生成(RAG)适用于您希望模型理解大量文档和上下文的情况。一般来说,如果您想为模型添加新知识,请选择RAG,而不是微调。如果您希望改变模型的行为、输出格式或整体态度,微调则是更好的选择。检索策略并不是微调的替代品,两者实际上可以相辅相成。
总结
微调GPT-4o mini为企业和开发者提供了一种定制AI功能的实用方法。本文介绍了微调过程的具体方法和关键步骤,包括从准备数据集到实施微调后的模型。
关键点包括:
- 数据质量至关重要。确保训练示例准确且与您的用例相关。
- 从适量的高质量数据开始,而不是追求大量数据。
- 使用OpenAI的平台进行微调过程非常简单。
- 对于许多应用,GPT-4o mini提供了一个经济高效的替代方案。
如同任何AI实现一样,设定现实的期望,并仔细测试您的微调模型是非常重要的。根据具体的用例和训练数据的质量,结果可能会有所不同。
总之,微调GPT-4o mini可以提升特定任务的性能,但并非万能解决方案。您需要仔细考虑目标,充分准备训练数据,并进行持续的评估和优化。随着微调成本的大幅降低,尝试不同的微调方法寻找模型的最佳表现,将变得更加重要。




