OpenAI 刚刚发布了 Sora,一种能够从文字描述生成视频的技术,从演示看,效果相当可以。Sora 模型的强大之处在于其能够根据文本描述,生成长达 60 秒的视频,其中包含精细复杂的场景、生动的角色表情以及复杂的镜头运动。
目前,Sora已对网络安全的红队成员开放,以评估其可能存在的风险或潜在伤害。同时,OpenAI 也邀请了视觉艺术家、设计师和电影制作人使用Sora,收集他们的反馈,以使模型更好地服务于创意行业。
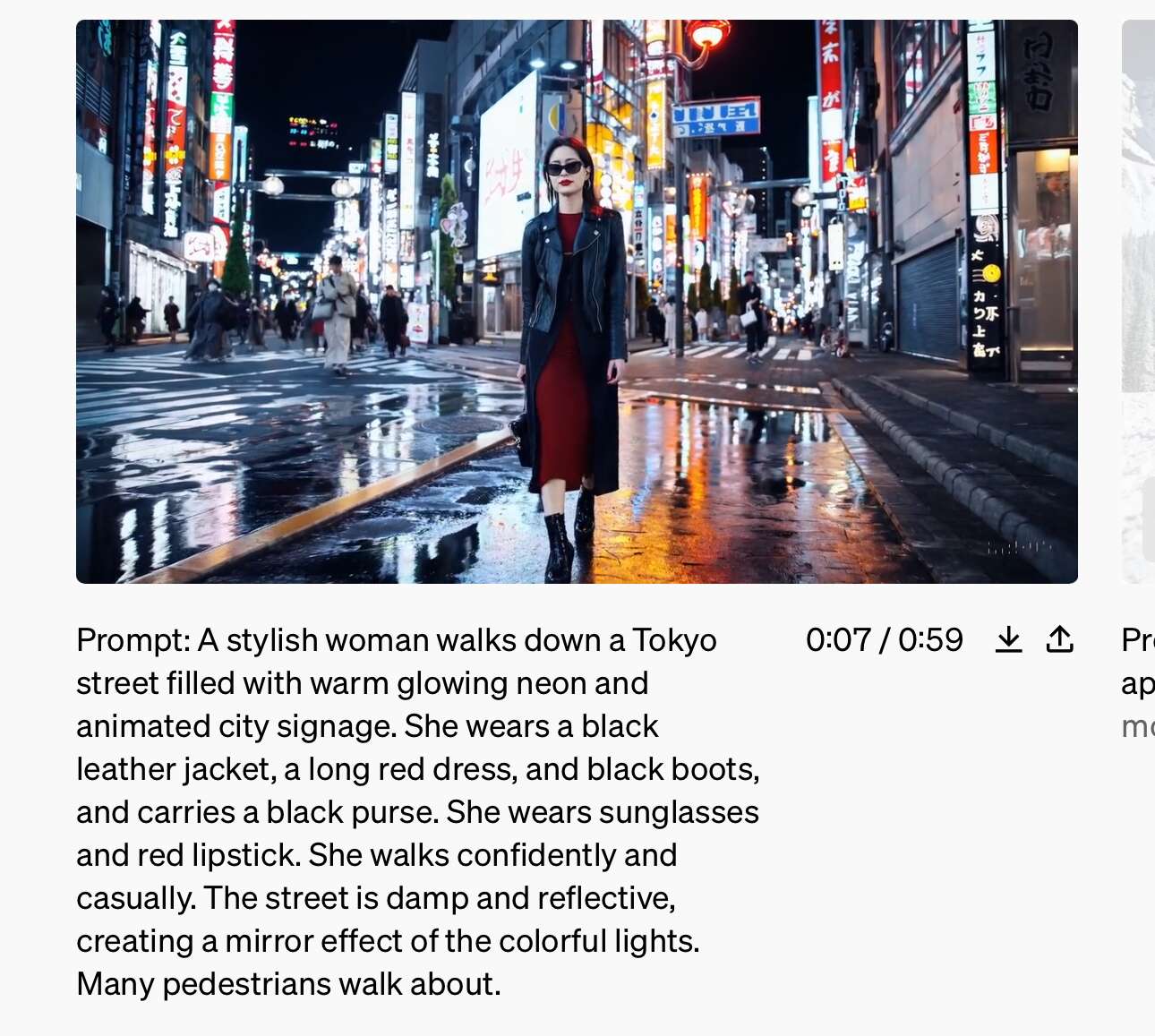
Sora能够创造出包含多个角色、特定动作类型以及与主题和背景相符的详细场景。这款模型不仅能理解用户的指令,还能洞察这些元素在现实世界中的表现。
Sora对语言有着深刻的理解,能够精准地捕捉到用户的需求,并创造出充满生命力、情感丰富的角色。此外,Sora还能在同一视频中创造出多个画面,同时保持角色和视觉风格的一致性。
演示视频 - 情侣观光樱花街头
该模型还能根据静态图像生成视频,以及在现有视频中填充缺失的帧或扩展视频。OpenAI 的博文中包含的 Sora 生成的演示包括淘金热时期加利福尼亚州的空中场景、从东京火车内部拍摄的视频等。许多演示都有人工智能的痕迹,比如在一段博物馆的视频中,地板疑似在移动。
OpenAI 表示,该模型"可能难以准确模拟复杂场景的物理现象",但总体而言,演示结果令人印象深刻。
当然,Sora还不是完美的。比如在模拟复杂场景的物理效应,以及理解某些特定因果关系时,它可能会遇到难题。举个例子,视频中的人物可能会咬一口饼干,但饼干上可能看不到明显的咬痕。
在处理空间细节,比如分辨左右时,Sora也可能会出现混淆;在精确描述一段时间内发生的事件,如特定的摄影机移动轨迹时,也可能显得力不从心。
不尽兴?OpenAI 官网发布了好几段演示视频,再来看看吧: