有人曾开玩笑说,互联网时代三分之二的技术进步是由宅圈需求驱动的。仔细想想,还真是这样。
以前,在线观看电影的需求彻底改变了数据传输技术。而在不久的将来,游戏宅男对5毛钱视觉效果的蔑视和对弱智NPC的鄙视,或许也可能同样改变元宇宙。

作为对于以上猜想的回应,行业大佬 Unity 笑了笑并宣布该公司在五年前就已经开始将 AI 技术用于游戏建模 和 NPC 制作。
是不是有一种“大家在山腰慢慢爬,我在山顶坐等”的自卑感?在大佬们争相花钱、企业拼命抢位的元宇宙激流中,Unity 有足够的实力在自己的游戏引擎中构建一个真实的虚拟现实世界。
事实上,Unity似乎并不担心令人苦恼的有关“元宇宙如何变现”的“世纪”问题。
元宇宙中的NPC
还记得《复仇者联盟4》最终决战的壮丽场景吗?这背后强大的渲染技术来自由著名导演彼得-杰克逊(Peter Jackson)创立的维塔数码(Weta Digital),它曾6次获得奥斯卡最佳视觉奖。
2021年11月上旬,Unity 宣布以 16.25 亿美元完成对 Weta Digital 的收购。于是,Unity 也开始在“元宇宙”的道路上飞速速驶。
不过,Unity 的高管们似乎并不适应,花了一些时日才得以豁然开朗:起初,他们只是想让游戏中的 NPC 看起来更逼真,并尽可能表现的必然不那么智障。
然而,公司高管逐渐发现,力求真实细腻的游戏建模以及NPC交互的AI引擎在现实世界中也可以得到应用,也就是说,其它企业和单位可以使用这些引擎来满足自己各种的需求。
这些企业输入的数据可以用来改进Unity的AI引擎,使Unity的虚拟建模逐渐成为现实世界的数字克隆版本。似乎在当下立刻就可以搭上元宇宙的便车。
说到元宇宙,不得不提的是 Unity 在 Open Technology Day 上揭示的关于数字人类的制作过程。
下面这位“现实版”小姐姐就是其中之一。她会撅嘴装可爱,皱眉生气,甚至让你诧异是不是该抛弃你二次元中的妻子。
但是,对于大规模量产的 NPC,还需要其他东西。
NPC是如何“变成人”的?
如果要将现实中的人融入元宇宙,显然需要大量多样性的标注数据,比如人物造型、姿势等。
然后,现成的数据集完全不可用。不仅数据量太小,其中涉及的隐私和偏见问题也饱受诟病。由于现实世界的数据不易使用,那我们不如自己合成吧。于是乎,一个新兴的替代方案诞生了,那就是“合成数据”。
然而,这个想法从一开始就遇到了障碍:合成数据的生成器很难搞定。
为此,Unity 推出了新的名为 “PeopleSansPeople”的解决方案。它包含具有高参数化的 3D 人体数据,可直接应用于模拟、参数化照明和拍摄系统、参数化环境生成器以及完全可操作和可扩展的领域随机生成器。
顾名思义,这个项目从随机抽取现实生活中的真实外观的数据开始,然后基于这些数据创建一个合成数据模型,让现实生活中的虚拟 NPC 更加逼真。
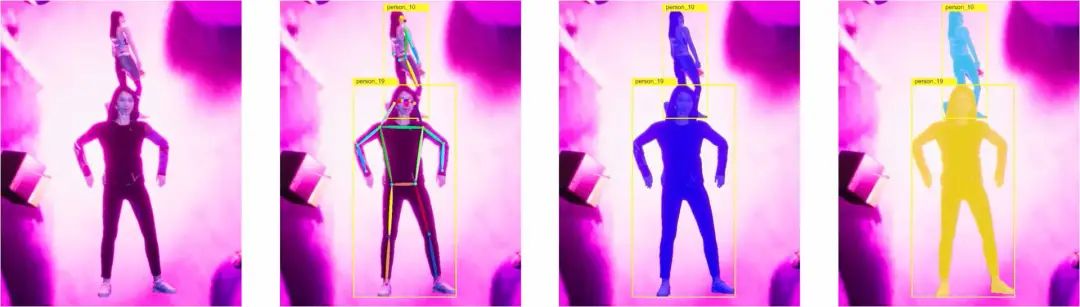
通过“PeopleSansPeople”,用户可以在JSON注释文件中生成带有完美匹配亚像素的2D/3D边界框的RGB图像、符合COCO标准的人体关键点以及语义/实例分割掩码。
此外,“PeopleSansPeople”还使用了 Detectron2 Key.point R-CNN 变体来进行基准合成数据的训练。

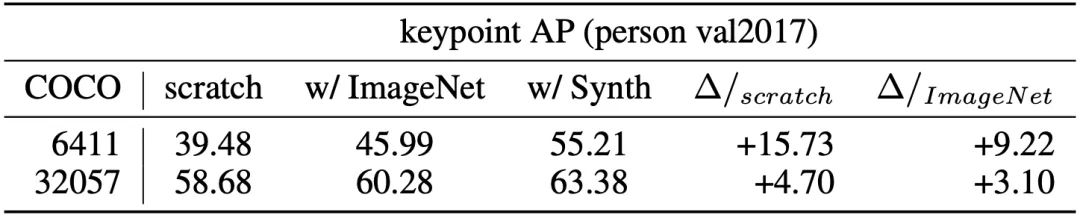
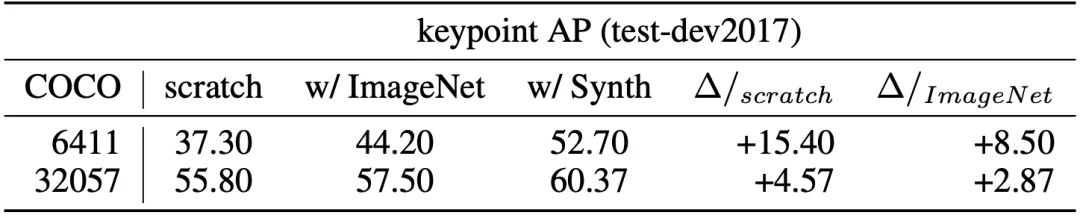
结果表明,用合成数据对网络进行预训练并微调目标真实世界数据后,关键点的AP得分可以达到60.37±0.48(COCO test-dev2017)。优于仅使用相同真实数据训练的模型 (55.80 AP) 和使用 ImageNet 预训练的模型 (57.50 AP)。
“PeopleSansPeople” 包含用于 macOS 和 Linux 系统上的大规模数据集(1M 或更多):
- 28个不同年龄和种族、不同服装的3D人体模型(21952个独特的服装纹理);
- 39个动画短片,人物姿势、体型等完全随机;
- 完全参数化的照明(位置、颜色、角度和强度)和拍摄(位置、场景、焦距)设置;
- 一组物体基元,作为分散注意力的物体和具有不同质地的遮挡物;
- 一组来自 COCO 的 1600 张未标记的自然图像作为对象的背景和纹理。
此外,PeopleSansPeople 还有一个 Unity 模板。用户可以将自己的 3D 数据导入到这个环境中,并通过修改或定义新的领域随机生成器来进一步提高其能力。

该模版除了具备之前数据集的所有功能外,还包括:
- 4个不同服装颜色的3D人体模型实例;
- 8个动画短片示例,具有完全随机的人体姿态等;
- 一组来自 Unity Perception 软件包的 529 张自然杂货图片作为物体的背景和纹理。

为了使模型能够扩展到真实领域,Unity通过额外的领域随机化来改变模拟环境,然后在合成数据中引入更多的变化。
即对三维物体的位置和姿态、场景中三维物体的纹理和颜色、灯光的配置和颜色、拍摄参数和一些后期效果等方面进行随机化处理。
其中,随机生成器在模拟过程中通过使用正态分布、均匀分布和二项分布从可能范围内采样来改变这些组件的参数。
此外,合成数据的训练不需要数据增强,这也加快了训练速度。因此,有了这样的工具,我们可以在即将成为NPC的模型山进行折腾了。
例如,使用“Unity Shader Graph”在衣服上生成形形色色的图案和模拟人体可以完成的各种动作和姿势。这样一来,应该能避免类似这种NPC的脑袋调转180度的情况吧。
现在,让我们回到 “PeopleSansPeople” 模型。使领域随机化,Unity 生成一个包含 500000 张图像和标签组成的复合数据集,并使用其中 490000 张图像进行训练,使用另外 10000 张图像进行验证。
相比COCO人物数据集,“PeopleSansPeople”在未标注的以及带有关键点的实例上,都多一个数量级。

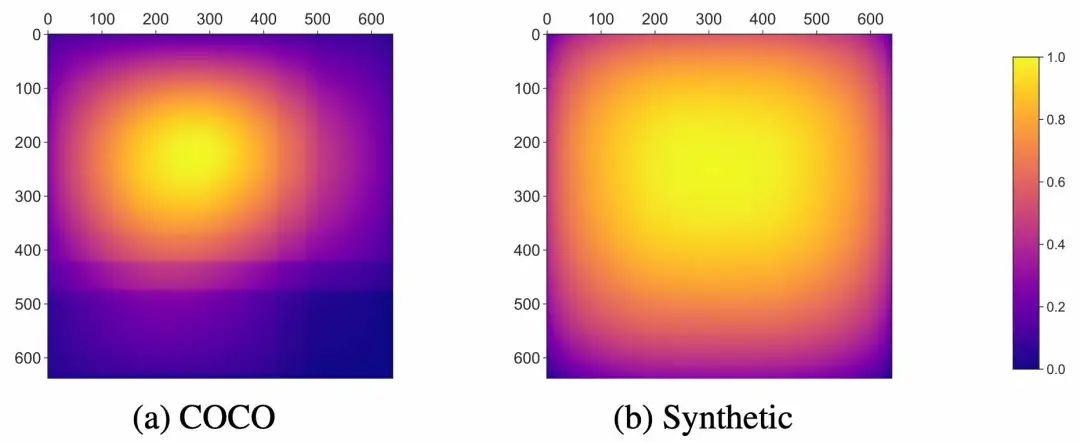
对于COCO数据集,由于有许多纵向和横向的图像,从而观察到了长方形的边界框分布随着图像的高度和宽度而下降。其中绝大多数图像的边界框都集中在中心附近,而很少向边缘扩散。
对于“PeopleSansPeople”的合成数据,这些边界框更倾向于占据整个图像框架,从而强迫模型去利用整个接受域。
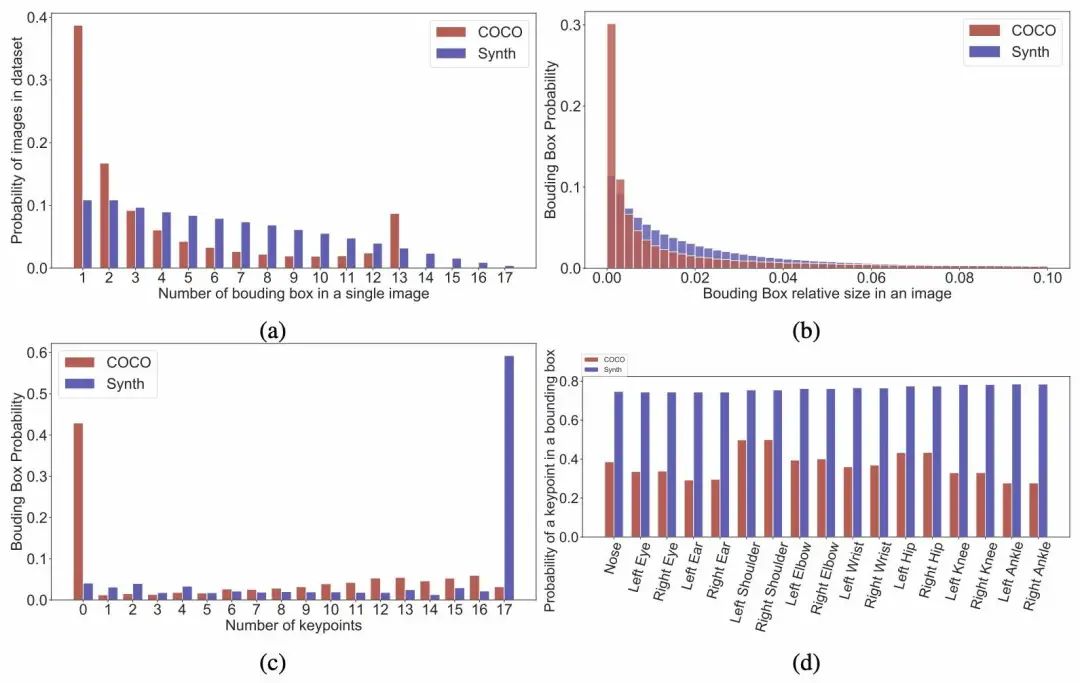
从统计数据可以看出,大多数COCO图像只有一两个边界框,而“PeopleSansPeople”数据集图像的边界框普遍较多。
“PeopleSansPeople”数据集的边界框尺寸分布较为均匀,而 COCO 的边界框大多非常小。此外,“PeopleSansPeople”数据集中的大部分边框都有关键点标注,而 COCO 没有。
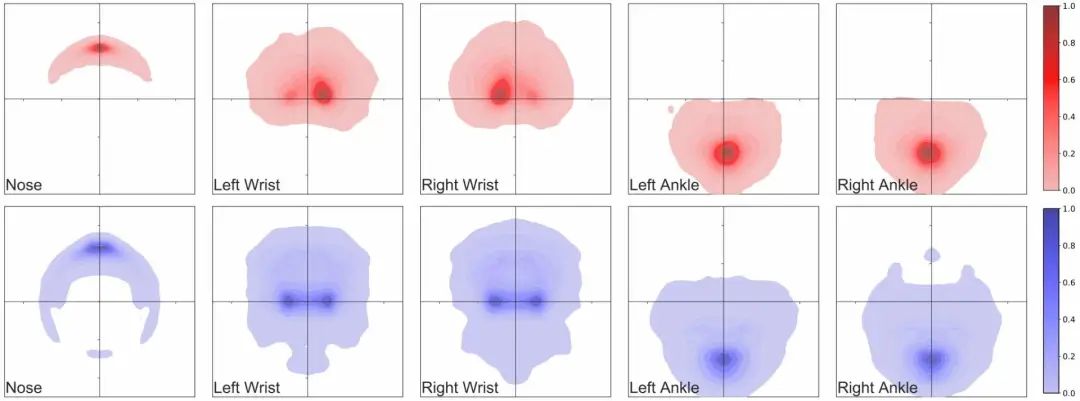
最后,为了量化 PeopleSansPeople 人体模型在生成图像中姿势的多样性,Unity对人物四肢的五个代表性关键点生成了姿势热图:
- PeopleSansPeople的姿势分布包含了COCO中的姿势分布;
- PeopleSansPeople的合成姿势分布比COCO更广泛;
- 在COCO中,大多数人是正面朝向的,导致了点的密度与「手性」的不对称,而这在PeopleSansPeople的合成数据中是没有的。
为了获得一套从模拟到真实的迁移学习的基准结果,Unity使用平均精度(AP)作为模型性能的主要指标,在COCO人物验证(person val2017)和测试集(test-dev2017)上进行了平局。
Unity通过随机初始化的权重和ImageNet预训练的权重来训练模型,并采用默认的参数范围来生成数据集,完全没有超参数的应用。
结果显示,PeopleSansPeople模型比那些只在真实数据上训练的模型或用ImageNet预训练然后在真实数据上微调的模型更好。
在真实数据有限的情况下,这种效果在 few-shot 迁移学习中更为突出。

此外,由于合成数据具有丰富的高质量标签,可以与很少或没有注释的真实数据相结合,实现弱监督训练。
展望
Unity AI项目负责人表示,在“PeopleSansPeople”项目中,虚拟NPC模型的最终姿势交互和视觉效果并不是实景截取的样本,实景数据只是模板库,最终模型是合成的。
这不仅避免了目前关于隐私的各种法律以及道德问题,也避免了 AI 数据偏见,这确实是建模的最佳选择。
Unity 不会缺少真实基础数据的合理合法来源,因为很多服务于海量流的企业和单位都与 Unity 拥有紧密合作,为其持续提供数据。Unity只需通过采用不涉及隐私的小举措,就可以极大地提升游戏项目中NPC的质量。不过,如果要将NPC做到以假乱真的真实人类水准,脚下还有很长的路需要走。