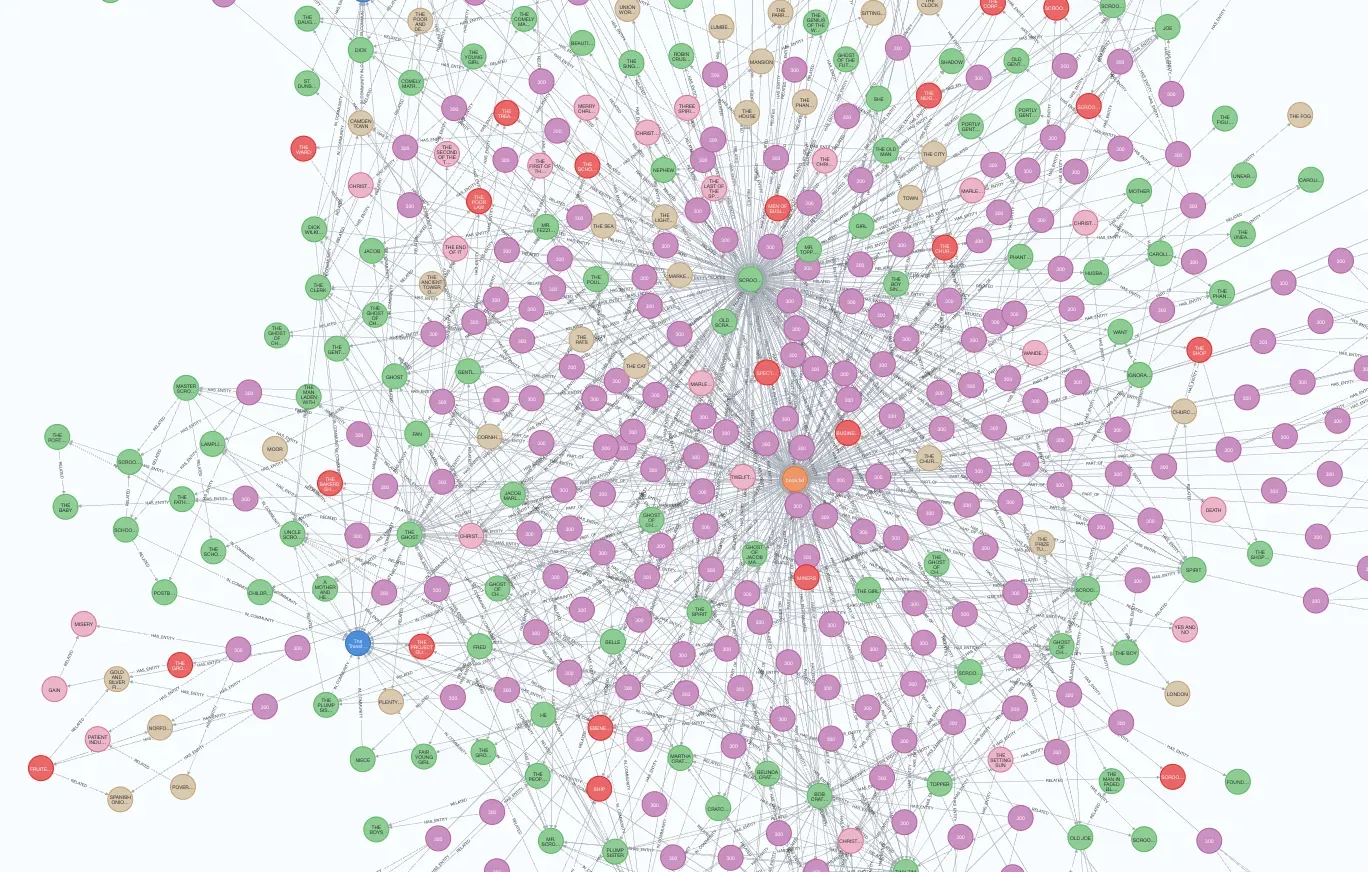
最近,Microsoft GraphRAG 项目引起了业界广泛关注,构建知识图谱也将逐步取代传统 RAG 技术。总体而言,GraphRAG 库的输入是包含各种信息的源文档,这些文档通过大型语言模型(LLM)处理,从中提取出文档中出现的实体及其关系的结构化信息。这些结构化信息随后用于构建知识图谱。
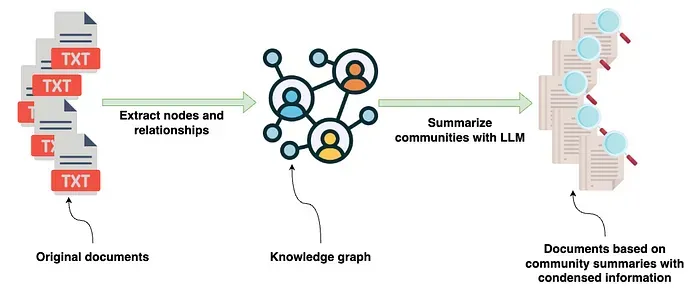
知识图谱构建完成后,GraphRAG 库结合了图算法(特别是 Leiden 社区检测算法)和 LLM 提示生成自然语言摘要,描述图谱中发现的实体和关系社区。
在本篇文章中,我们将把 GraphRAG 库的输出存储在 Neo4j 中,然后使用 LangChain 和 LlamaIndex 框架直接从 Neo4j 中形成检索器。
代码和 GraphRAG 输出结果可以在 GitHub 上访问,这样你可以跳过 GraphRAG 提取过程。
数据集
本文中使用的数据集是查尔斯·狄更斯的《圣诞颂歌》,可以通过古登堡计划免费获取。

我们之所以选择这本书作为数据源,主要是因为它在各类入门指引中被广泛使用,这将使得提取过程变得更加轻松。
图谱构建
尽管你可以跳过图谱提取部分,但我依然想讨论一些我认为最重要的配置选项。比如,图谱提取可能非常耗费令牌和成本。因此,选择像 gpt-4o-mini 这样相对便宜但性能良好的 LLM 进行测试是最好的。与 gpt-4-turbo 相比,成本显著降低,同时仍保持良好的准确性。
GRAPHRAG_LLM_MODEL=gpt-4o-mini
最重要的配置是我们想要提取的实体类型。默认情况下,提取的是组织、人物、事件和地理信息。
GRAPHRAG_ENTITY_EXTRACTION_ENTITY_TYPES=organization,person,event,geo
这些默认实体类型对于书籍可能非常适用,但请确保根据你正在处理的文档领域调整它们。
另一个重要配置是最大提取次数(max gleanings)值。作者发现并且我们也单独验证过,LLM 在单次提取中无法提取所有可用信息。
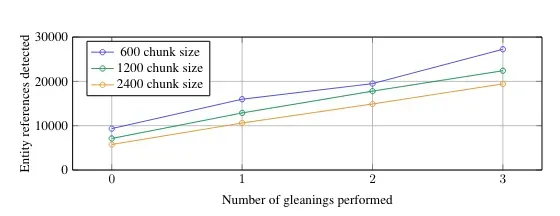
通过提取配置,LLM 可以执行多次提取。上图清楚地显示出,进行多次提取(gleanings)可以提取更多信息。多次提取非常耗费令牌,因此像 gpt-4o-mini 这样便宜的模型有助于保持低成本。
GRAPHRAG_ENTITY_EXTRACTION_MAX_GLEANINGS=1
此外,默认情况下并不会提取声明或协变量信息。你可以通过设置 GRAPHRAG_CLAIM_EXTRACTION_ENABLED 配置来启用它。
GRAPHRAG_CLAIM_EXTRACTION_ENABLED=False
GRAPHRAG_CLAIM_EXTRACTION_MAX_GLEANINGS=1
同样,LLM 在单次提取中不会提取所有结构化信息,因此我们在此处也有提取配置选项。
值得注意的是,提示调优(prompt tuning)部分也很有意思,尽管我还没来得及深入研究。提示调优是可选的,但强烈建议进行,因为它可以提高准确性。有关提示调优的更多信息请参考:
在设置完配置后,我们可以按照说明运行图谱提取管道,步骤如下图所示:
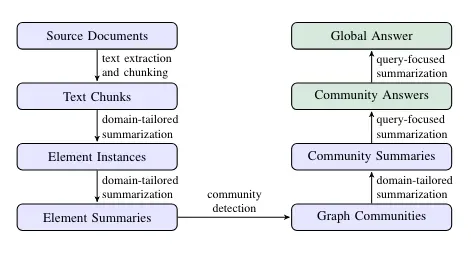
图谱提取管道执行了上图中所有蓝色的步骤。想了解更多关于图谱构建和社区摘要的内容,请查看我之前的博文。Microsoft GraphRAG 库的图谱提取管道输出的是一组 parquet 文件,如 Operation Dulce 示例所示。
这些 parquet 文件可以轻松导入 Neo4j 图数据库,用于后续分析、数据可视化和检索。我们可以使用免费的云端 Aura 实例,或搭建本地 Neo4j 环境。我们将在本文中通过导入五六个 CSV 文件到 Neo4j 中来构建知识图谱。
Jupyter notebook 代码及 GraphRAG 输出示例,我已经把它放在了这里。完成导入后,我们可以打开 Neo4j 浏览器验证并可视化导入的图谱部分。
图谱分析
在实现检索器之前,我们将进行简单的图谱分析,以熟悉提取的数据。我们从定义数据库连接和执行 Cypher 语句(图数据库查询语言)并输出 Pandas DataFrame 的函数开始。
NEO4J_URI="bolt://localhost"
NEO4J_USERNAME="neo4j"
NEO4J_PASSWORD="password"
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
def db_query(cypher: str, params: Dict[str, Any] = {}) -> pd.DataFrame:
"""Executes a Cypher statement and returns a DataFrame"""
return driver.execute_query(
cypher, parameters_=params, result_transformer_=Result.to_df
)
在执行图谱提取时,我们使用了 300 的块大小。自那以后,作者将默认块大小更改为 1200。我们可以使用以下 Cypher 语句验证块大小。
db_query(
"MATCH (n:__Chunk__) RETURN n.n_tokens as token_count, count(*) AS count"
)
# token_count count
# 300 230
# 155 1
230 个块有 300 个令牌,而最后一个块只有 155 个令牌。现在我们检查一个示例实体及其描述。
db_query(
"MATCH (n:__Entity__) RETURN n.name AS name, n.description AS description LIMIT 1"
)
结果

看起来古登堡计划在书中某处被描述,可能是在开头部分。我们可以看到描述比单纯的实体名称捕获了更多细致和复杂的信息,这正是 Microsoft GraphRAG 论文中提出的,旨在保留文本中的更复杂和细微数据。
我们还可以检查示例关系。
db_query(
"MATCH ()-[n:RELATED]->() RETURN n.description AS description LIMIT 5"
)
结果

Microsoft GraphRAG 不仅仅提取实体之间的简单关系类型,还捕获了详细的关系描述。这种能力使得它能够比简单的关系类型捕获更多细微信息。
我们还可以检查一个社区及其生成的描述。
db_query("""
MATCH (n:__Community__)
RETURN n.title AS title, n.summary AS summary, n.full_content AS full_content LIMIT 1
""")
结果

一个社群(群组)有一个标题、摘要和使用 LLM 生成的完整内容。我还没看到作者在检索过程中是使用完整内容还是仅使用摘要,但我们可以在两者之间进行选择。我们可以观察到完整内容中引用了来自实体和关系的信息源。有趣的是,当引用过长时,LLM 有时会进行裁剪,如以下示例所示。
[Data: Entities (11, 177); Relationships (25, 159, 20, 29, +more)]
无法展开 +more 标志,这是一种 LLM 处理长引用的有趣方式。
现在让我们评估一些分布情况。首先,我们将检查从文本块中提取的实体数量的分布。
entity_df = db_query(
"""
MATCH (d:__Chunk__)
RETURN count {(d)-[:HAS_ENTITY]->()} AS entity_count
"""
)
# 绘制分布图
plt.figure(figsize=(10, 6))
sns.histplot(entity_df['entity_count'], kde=True, bins=15, color='skyblue')
plt.axvline(entity_df['entity_count'].mean(), color='red', linestyle='dashed', linewidth=1)
plt.axvline(entity_df['entity_count'].median(), color='green', linestyle='dashed', linewidth=1)
plt.xlabel('实体数量', fontsize=12)
plt.ylabel('频率', fontsize=12)
plt.title('实体数量分布', fontsize=15)
plt.legend({'平均值': entity_df['entity_count'].mean(), '中位数': entity_df['entity_count'].median()})
plt.show()
结果
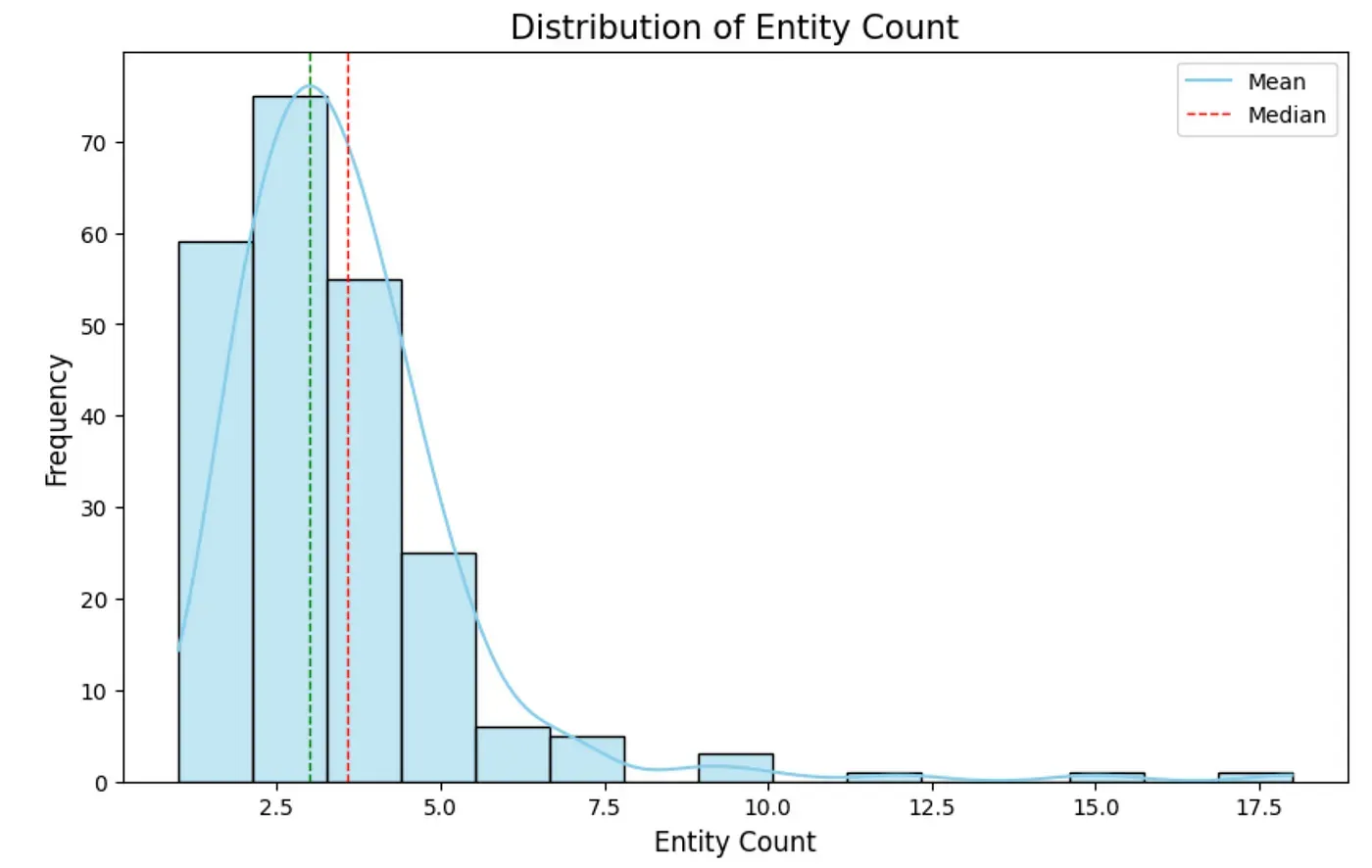
记住,文本块有 300 个令牌。因此,提取的实体数量相对较少,每个文本块平均约有三个实体。提取是在没有任何 gleanings(单次提取)的情况下完成的。如果我们增加 gleanings 次数,查看分布情况会很有趣。
接下来,我们将评估节点度分布。节点度是一个节点的关系数量。
degree_dist_df = db_query(
"""
MATCH (e:__Entity__)
RETURN count {(e)-[:RELATED]-()} AS node_degree
"""
)
# Calculate mean and median
mean_degree = np.mean(degree_dist_df['node_degree'])
percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90])
# Create a histogram with a logarithmic scale
plt.figure(figsize=(12, 6))
sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue')
# Use a logarithmic scale for the x-axis
plt.yscale('log')
# Adding labels and title
plt.xlabel('Node Degree')
plt.ylabel('Count (log scale)')
plt.title('Node Degree Distribution')
# Add mean, median, and percentile lines
plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}')
plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}')
plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}')
plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}')
plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}')
# Add legend
plt.legend()
# Show the plot
plt.show()结果
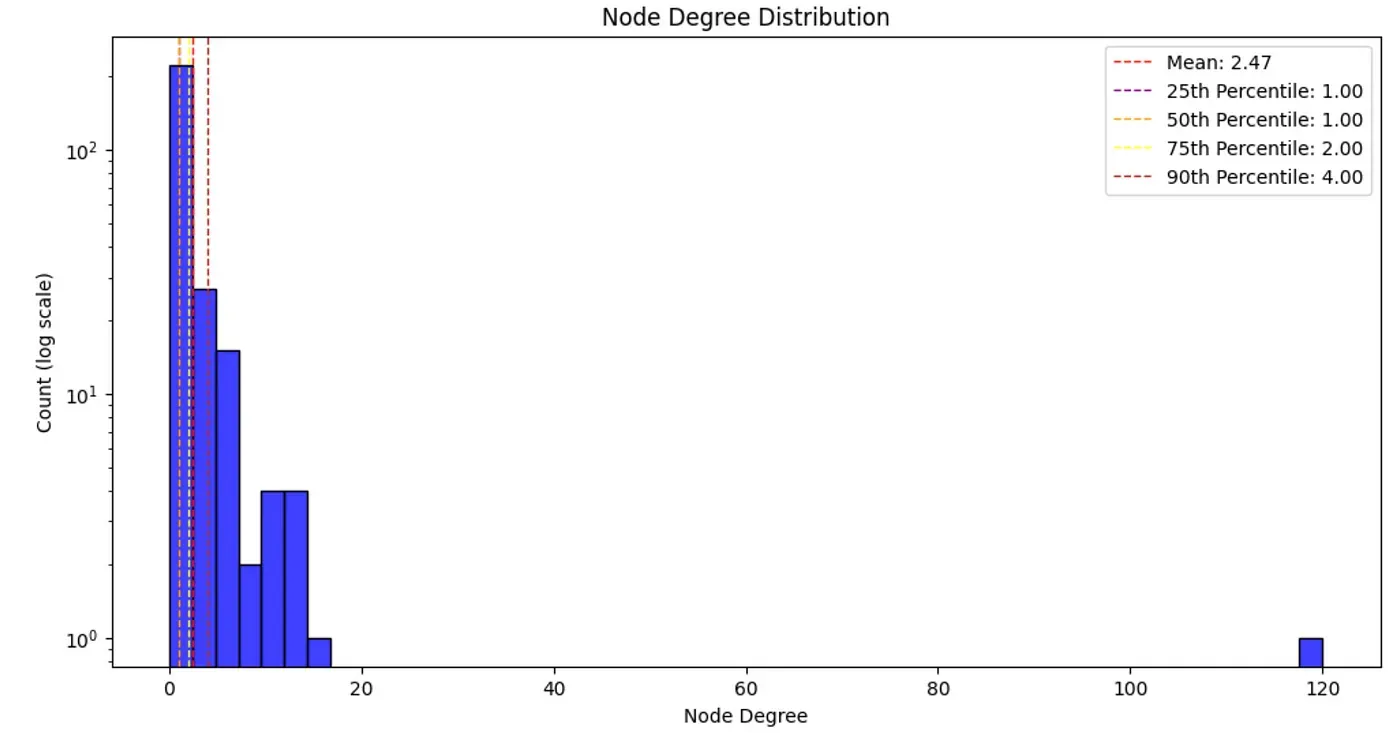
大多数现实世界的网络遵循幂律节点度分布,其中大部分节点的度数相对较小,而一些重要节点则具有较高的度数。尽管我们的图谱较小,但节点度分布依然符合幂律分布。找到拥有120个关系(连接到43%的实体)的实体是非常有趣的。
db_query("""
MATCH (n:__Entity__)
RETURN n.name AS name, count{(n)-[:RELATED]-()} AS degree
ORDER BY degree DESC LIMIT 5""")结果
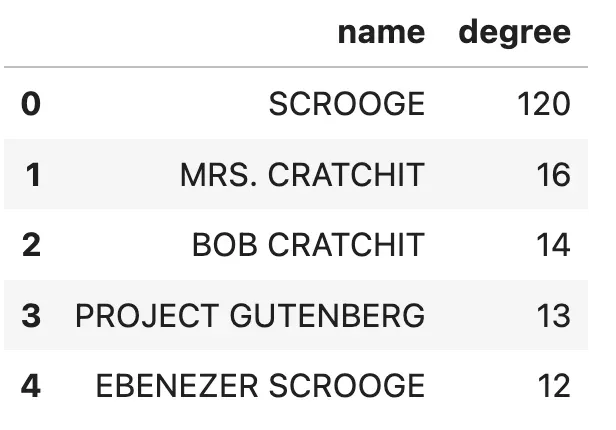
毫无疑问,我们可以推测出 Scrooge 是这本书的主角。我还大胆猜测 Ebenezer Scrooge 和 Scrooge 其实是同一个实体,但由于 MSFT GraphRAG 没有进行实体解析步骤,它们未被合并。
这也表明,分析和清理数据是减少噪声信息的关键步骤。比如,尽管 Project Gutenberg 并非书中故事的一部分,但它却有13个关系。
最后,我们将检查每个层级中社区规模的分布情况。
community_data = db_query("""
MATCH (n:__Community__)
RETURN n.level AS level, count{(n)-[:IN_COMMUNITY]-()} AS members
""")
stats = community_data.groupby('level').agg(
min_members=('members', 'min'),
max_members=('members', 'max'),
median_members=('members', 'median'),
avg_members=('members', 'mean'),
num_communities=('members', 'count'),
total_members=('members', 'sum')
).reset_index()
# Create box plot
plt.figure(figsize=(10, 6))
sns.boxplot(x='level', y='members', data=community_data, palette='viridis')
plt.xlabel('Level')
plt.ylabel('Members')
# Add statistical annotations
for i in range(stats.shape[0]):
level = stats['level'][i]
max_val = stats['max_members'][i]
text = (f"num: {stats['num_communities'][i]}\n"
f"all_members: {stats['total_members'][i]}\n"
f"min: {stats['min_members'][i]}\n"
f"max: {stats['max_members'][i]}\n"
f"med: {stats['median_members'][i]}\n"
f"avg: {stats['avg_members'][i]:.2f}")
plt.text(level, 85, text, horizontalalignment='center', fontsize=9)
plt.show()结果
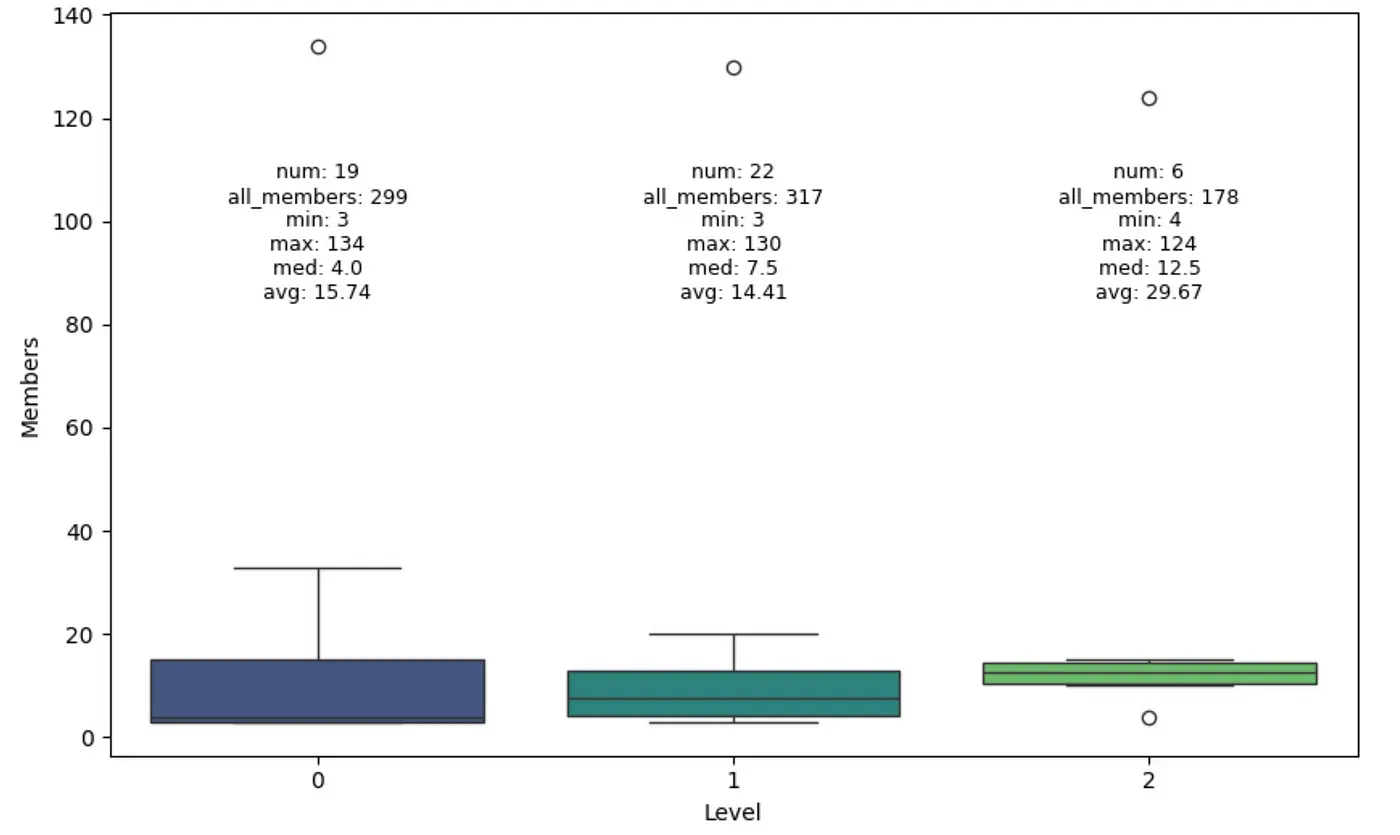
Leiden 算法识别出三个层级的社区,其中较高级别的社区平均规模更大。然而,仍有一些技术细节我尚不清楚,因为查看总节点数量时,每个层级的节点数不尽相同,而理论上它们应该相同。此外,如果社区在更高级别上合并,为什么第0级有19个社区,而第1级有22个?作者在这里做了一些优化和技巧,我还没来得及详细探索。
实现检索器
在本文的最后部分,我们将讨论 MSFT GraphRAG 中指定的本地和全局检索器。这些检索器将与 LangChain 和 LlamaIndex 集成。
本地检索器
本地检索器首先使用向量搜索识别相关节点,然后收集相关信息并将其注入到 LLM 提示中。
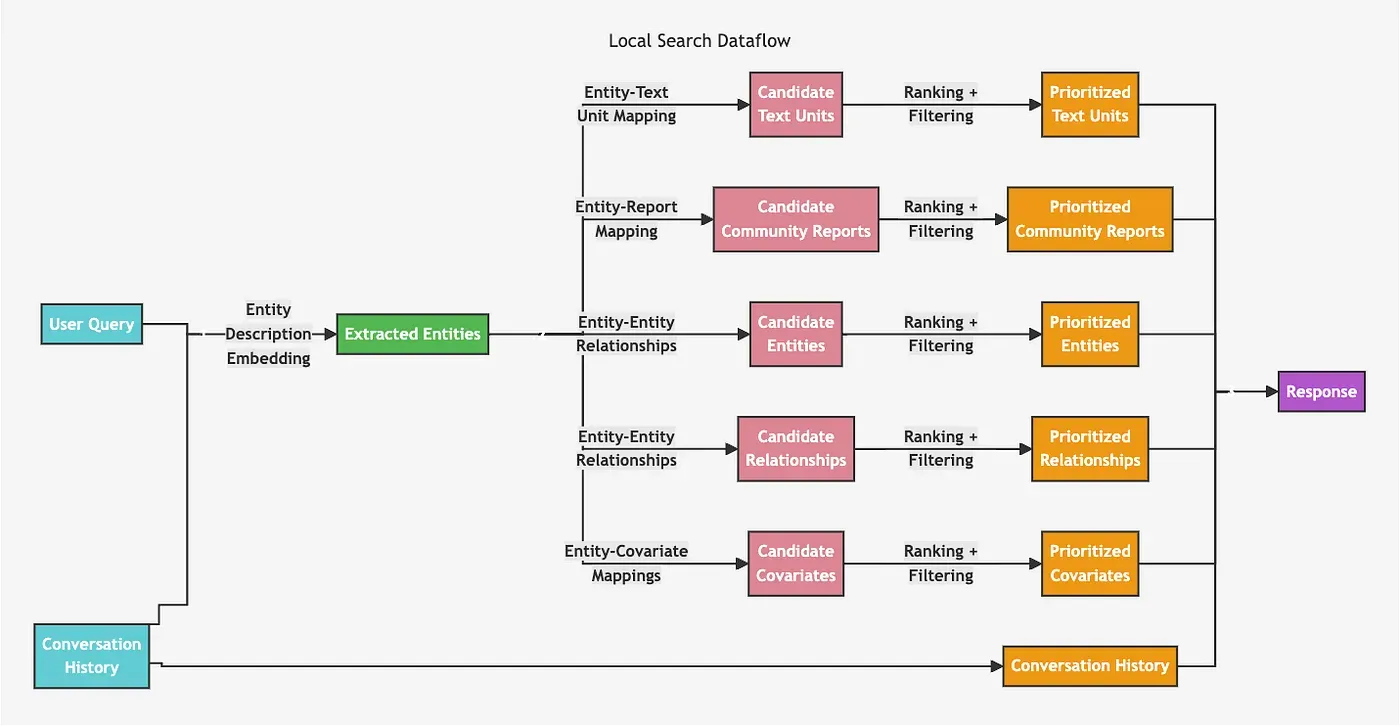
虽然上图看起来很复杂,但实现起来并不难。我们从使用基于实体描述文本嵌入的向量相似性搜索识别相关实体开始。一旦识别出相关实体,我们可以遍历与其相关的文本块、关系、社区摘要等。使用向量相似性搜索并遍历整个图谱的模式可以通过 LangChain 和 LlamaIndex 中的 retrieval_query 功能轻松实现。
首先,我们需要配置向量索引。
index_name = "entity"
db_query(
"""
CREATE VECTOR INDEX """
+ index_name
+ """ IF NOT EXISTS FOR (e:__Entity__) ON e.description_embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
"""
)我们还会计算并存储社区权重,它定义为社区中实体出现在不同文本块中的次数。
db_query(
"""
MATCH (n:`__Community__`)<-[:IN_COMMUNITY]-()<-[:HAS_ENTITY]-(c)
WITH n, count(distinct c) AS chunkCount
SET n.weight = chunkCount"""
)各部分候选项(文本单元、社区报告等)的数量是可配置的。尽管原始实现中基于令牌数量的过滤稍微复杂一些,但我们在这里简化了它。我根据默认配置值开发了以下简化的顶级候选项过滤值。
topChunks = 3
topCommunities = 3
topOutsideRels = 10
topInsideRels = 10
topEntities = 10我们将从 LangChain 的实现开始。我们唯一需要定义的是 `retrieval_query`,它较为复杂。
lc_retrieval_query = """
WITH collect(node) as nodes
// Entity - Text Unit Mapping
WITH
collect {
UNWIND nodes as n
MATCH (n)<-[:HAS_ENTITY]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN c.text AS chunkText
ORDER BY freq DESC
LIMIT $topChunks
} AS text_mapping,
// Entity - Report Mapping
collect {
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY]->(c:__Community__)
WITH c, c.rank as rank, c.weight AS weight
RETURN c.summary
ORDER BY rank, weight DESC
LIMIT $topCommunities
} AS report_mapping,
// Outside Relationships
collect {
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE NOT m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT $topOutsideRels
} as outsideRels,
// Inside Relationships
collect {
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT $topInsideRels
} as insideRels,
// Entities description
collect {
UNWIND nodes as n
RETURN n.description AS descriptionText
} as entities
// We don't have covariates or claims here
RETURN {Chunks: text_mapping, Reports: report_mapping,
Relationships: outsideRels + insideRels,
Entities: entities} AS text, 1.0 AS score, {} AS metadata
"""
lc_vector = Neo4jVector.from_existing_index(
OpenAIEmbeddings(model="text-embedding-3-small"),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=index_name,
retrieval_query=lc_retrieval_query
)这个 Cypher 查询对一组节点执行多个分析操作,以提取并组织相关文本数据:
-
实体-文本单元映射:查询识别链接的文本块(
__Chunk__),按与每个块相关的不同节点数进行聚合,并按频率排序。返回前几个文本块作为text_mapping。 -
实体-报告映射:查询查找与节点相关的社区(
__Community__),并根据排名和权重返回排名靠前的社区摘要。 -
外部关系:此部分提取描述关系(
RELATED)的文本,其中相关实体(m)不在初始节点集中。关系按排名排序,限于返回前几个外部关系。 -
内部关系:与外部关系类似,但这次仅考虑初始节点集内的关系。
-
实体描述:收集初始节点集中每个节点的描述。
最终,查询将收集的数据组合成结构化结果,包括文本块、报告、内部和外部关系以及实体描述,同时返回默认评分和空的元数据对象。你可以选择删除一些检索部分,测试它们对结果的影响。
现在,你可以使用以下代码来运行检索器:
docs = lc_vector.similarity_search(
"What do you know about Cratchitt family?",
k=topEntities,
params={
"topChunks": topChunks,
"topCommunities": topCommunities,
"topOutsideRels": topOutsideRels,
"topInsideRels": topInsideRels,
},
)
# print(docs[0].page_content)最近,我在尝试实现 LlamaIndex 中的相同检索模式时,发现我们首先需要为节点添加元数据,以便向量索引能够正常工作。如果没有将默认元数据添加到相关节点中,向量索引将会报错。
# https://github.com/run-llama/llama_index/blob/main/llama-index-core/llama_index/core/vector_stores/utils.py#L32
from llama_index.core.schema import TextNode
from llama_index.core.vector_stores.utils import node_to_metadata_dict
content = node_to_metadata_dict(TextNode(), remove_text=True, flat_metadata=False)
db_query(
"""
MATCH (e:__Entity__)
SET e += $content""",
{"content": content},
)
然后,我们可以使用 LlamaIndex 中的 retrieval_query 特性来定义检索器。与 LangChain 不同的是,我们将使用 f-string 而不是查询参数来传递顶级候选过滤参数。
retrieval_query = f"""
WITH collect(node) as nodes
// Entity - Text Unit Mapping
WITH
nodes,
collect {{
UNWIND nodes as n
MATCH (n)<-[:HAS_ENTITY]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN c.text AS chunkText
ORDER BY freq DESC
LIMIT {topChunks}
}} AS text_mapping,
// Entity - Report Mapping
collect {{
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY]->(c:__Community__)
WITH c, c.rank as rank, c.weight AS weight
RETURN c.summary
ORDER BY rank, weight DESC
LIMIT {topCommunities}
}} AS report_mapping,
// Outside Relationships
collect {{
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE NOT m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT {topOutsideRels}
}} as outsideRels,
// Inside Relationships
collect {{
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT {topInsideRels}
}} as insideRels,
// Entities description
collect {{
UNWIND nodes as n
RETURN n.description AS descriptionText
}} as entities
// We don't have covariates or claims here
RETURN "Chunks:" + apoc.text.join(text_mapping, '|') + "\nReports: " + apoc.text.join(report_mapping,'|') +
"\nRelationships: " + apoc.text.join(outsideRels + insideRels, '|') +
"\nEntities: " + apoc.text.join(entities, "|") AS text, 1.0 AS score, nodes[0].id AS id, {{_node_type:nodes[0]._node_type, _node_content:nodes[0]._node_content}} AS metadata
"""
需要注意的是,返回值略有不同。我们需要返回节点类型和内容作为元数据,否则检索器将会崩溃。接下来,我们只需实例化 Neo4j 向量存储并将其用作查询引擎。
neo4j_vector = Neo4jVectorStore(
NEO4J_USERNAME,
NEO4J_PASSWORD,
NEO4J_URI,
embed_dim,
index_name=index_name,
retrieval_query=retrieval_query,
)
loaded_index = VectorStoreIndex.from_vector_store(neo4j_vector).as_query_engine(
similarity_top_k=topEntities, embed_model=OpenAIEmbedding(model="text-embedding-3-large")
)
现在我们可以测试 GraphRAG 本地检索器。
response = loaded_index.query("What do you know about Scrooge?")
print(response.response)
输出示例:
Scrooge is an employee who is impacted by the generosity and festive spirit
of the Fezziwig family, particularly Mr. and Mrs. Fezziwig. He is involved
in the memorable Domestic Ball hosted by the Fezziwigs, which significantly
influences his life and contributes to the broader narrative of kindness
and community spirit.
我们可以立即想到,通过使用混合方法(向量 + 关键词)来查找相关实体,而不是仅使用向量搜索,可以提升本地检索的效果。
全局检索器
全局检索器的架构相对简单一些,主要思路是遍历指定层级的所有社区摘要,生成中间摘要,然后基于这些中间摘要生成最终结果。
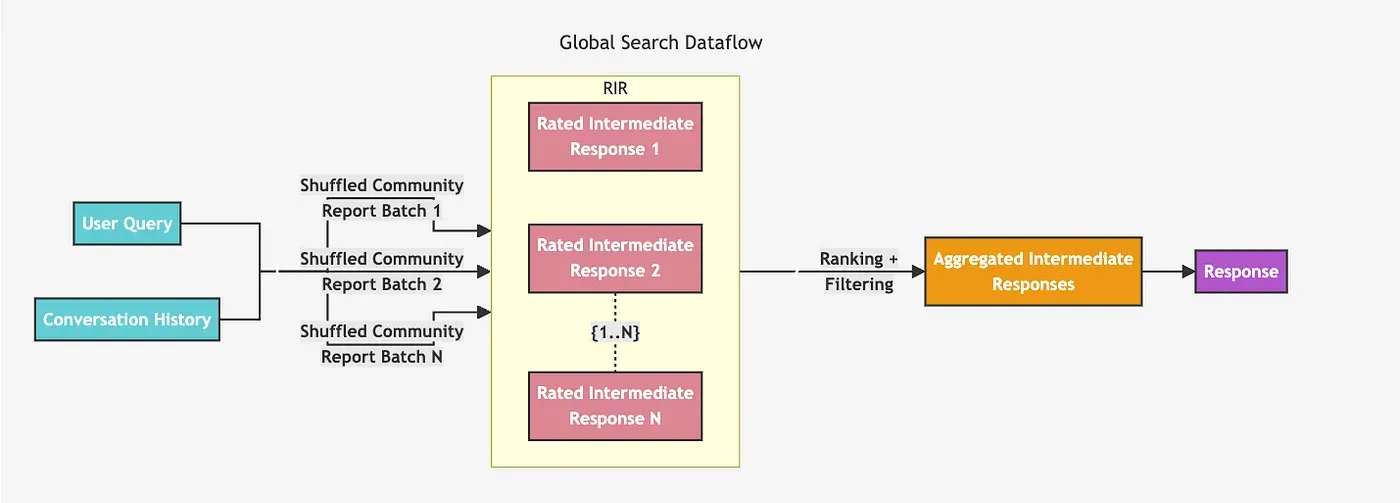
我们需要提前决定遍历哪个层级的社区,这并不是一个简单的决定,因为我们不清楚哪个层级效果更好。层级越高,社区越大,但数量更少。这是我们在不手动检查摘要的情况下唯一能得到的信息。
其他参数允许我们忽略低于某个排名或权重阈值的社区,但我们在此不会使用这些参数。我们将使用 LangChain 实现全局检索器,并使用 GraphRAG 论文中的相同 map 和 reduce 提示。由于系统提示内容很长,我们这里不包括它们或链式结构构建。然而,所有代码都在 notebook 中可用。
def global_retriever(query: str, level: int, response_type: str = response_type) -> str:
community_data = graph.query(
"""
MATCH (c:__Community__)
WHERE c.level = $level
RETURN c.full_content AS output
""",
params={"level": level},
)
intermediate_results = []
for community in tqdm(community_data, desc="Processing communities"):
intermediate_response = map_chain.invoke(
{"question": query, "context_data": community["output"]}
)
intermediate_results.append(intermediate_response)
final_response = reduce_chain.invoke(
{
"report_data": intermediate_results,
"question": query,
"response_type": response_type,
}
)
return final_response
测试一下:
print(global_retriever("What is the story about?", 2))
结果
The story primarily revolves around Ebenezer Scrooge, a miserly man who initially embodies a cynical outlook towards life and despises Christmas. His transformation begins when he is visited by the ghost of his deceased business partner, Jacob Marley, followed by the appearances of three spirits—representing Christmas Past, Present, and Yet to Come. These encounters prompt Scrooge to reflect on his life and the consequences of his actions, ultimately leading him to embrace the Christmas spirit and undergo significant personal growth [Data: Reports (32, 17, 99, 86, +more)].
### The Role of Jacob Marley and the Spirits
Jacob Marley's ghost serves as a supernatural catalyst, warning Scrooge about the forthcoming visitations from the three spirits. Each spirit guides Scrooge through a journey of self-discovery, illustrating the impact of his choices and the importance of compassion. The spirits reveal to Scrooge how his actions have affected not only his own life but also the lives of others, particularly highlighting the themes of redemption and interconnectedness [Data: Reports (86, 17, 99, +more)].
### Scrooge's Relationships and Transformation
Scrooge's relationship with the Cratchit family, especially Bob Cratchit and his son Tiny Tim, is pivotal to his transformation. Through the visions presented by the spirits, Scrooge develops empathy, which inspires him to take tangible actions that improve the Cratchit family's circumstances. The narrative emphasizes that individual actions can have a profound impact on society, as Scrooge's newfound generosity fosters compassion and social responsibility within his community [Data: Reports (25, 158, 159, +more)].
### Themes of Redemption and Hope
Overall, the story is a timeless symbol of hope, underscoring themes such as empathy, introspection, and the potential for personal change. Scrooge's journey from a lonely miser to a benevolent figure illustrates that it is never too late to change; small acts of kindness can lead to significant positive effects on individuals and the broader community [Data: Reports (32, 102, 126, 148, 158, 159, +more)].简而言之,这个故事体现了圣诞节的变革力量和人际关系的重要性,使其成为一个关于救赎的感人叙事,以及一个人在假期期间对他人可能产生的影响。
结果相当长且详尽,因为它适用于一个全局检索器,该检索器遍历指定层级上的所有社区。你可以通过改变社区的层级结构来测试结果会如何变化。
总结
在这篇文章中,我们演示了如何将 Microsoft 的 GraphRAG 集成到 Neo4j 中,并使用 LangChain 和 LlamaIndex 实现检索器。本地检索器结合了向量相似性搜索和图谱遍历,而全局检索器则遍历社区摘要以生成全面的结果。此实现展示了将结构化知识图谱与语言模型结合以增强信息检索和问答的强大功能。
本文所有代码可以在下方获取:
 tomasonjo
tomasonjo