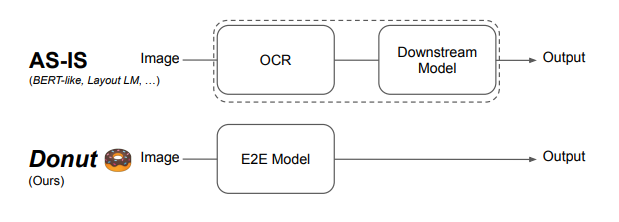
Document Understanding Transformer ,是一种新的文档理解方法,它利用了无 OCR 的端到端 Transformer 模型。Donut 不需要现成的 OCR 引擎/API,但它在各种视觉(可视化)文档理解任务——例如视觉文档分类或信息提取(又名文档解析)上展示了最先进的性能。也就是说,Donut 不做 OCR,直接对图片进行文字信息抽取(也叫文档理解)。
理解文档图像(如发票)一直是个重要的研究课题,在文档处理自动化方面有许多应用。通过基于深度学习的光学字符识别(OCR)的最新进展,目前的视觉文档理解(VDU)系统已经开始基于 OCR 设计。尽管这种基于OCR的方法承诺了合理的性能,但它们受到OCR引起的关键问题的影响。主要体现为昂贵的计算成本以及由于OCR错误传播导致的性能下降。
本文提出一种新的VDU模型,在没有OCR框架支持的情况下可以进行端到端训练。提出了一个新的任务和一个合成文档图像生成器来预训练模型,以减轻对大规模真实文档图像的依赖。该方法在公共基准数据集和私有商用服务数据集的各种文档理解任务中取得了最先进的性能。通过广泛的实验和分析,证明了所提出的模型的有效性,特别是考虑到了现实世界的应用。
下面开始针对 Donut 展开分析。
特点
- 视觉文档理解模型,使用单个端到端模型一步完成OCR+下游任务。
- 输出是生成式的,并且可转换为 JSON 格式,这使得该架构与各种下游任务高度兼容。
- SynthDoG 展现——合成文档图像生成器在本项目中得到使用。
整体结构
虽然之前普遍采用了两阶段方法,首先提取文本,然后使用文本作为输入和输出所需文档信息的模型,但本项目建议一次性完成这两个单独的任务。得益于本特性,使得本项目在速度方面完胜之前的方案。

模型架构由视频编码器与文本解码器组成。
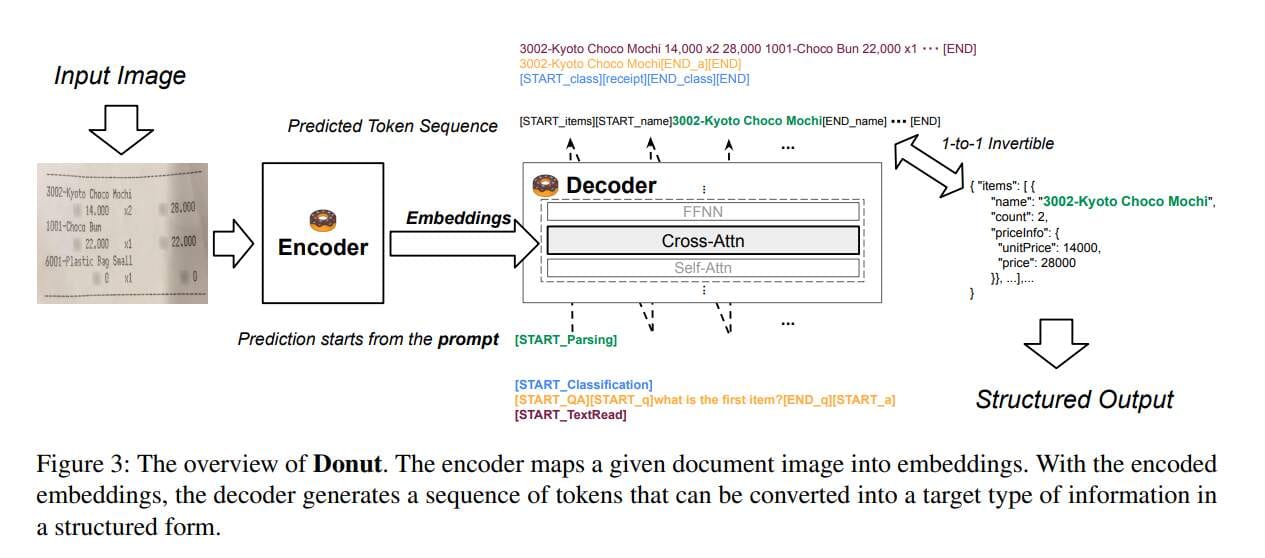
视觉编码器
将输入图像(HxWxC)转换为嵌入式特征(Nxd),其中使用 N=特征映射大小(最终特征映射的宽度x高度)swin 转换器。作者未提及特定的输入图像大小。
文本解码器
使用多语言 BART 作为解码器架构,出于速度/内存考虑,只使用了 BART 前4层。
着重于文本输入序列和视觉编码器输出(视觉嵌入)之间的交叉关注。由于基于解码器,所以具备自回归特性。
模型输入与输出
该模型需要两个输入:
- 图像
- 带有提示的文本
文本输入因下游任务而异,使用特殊的令牌来表示特定任务。如果任务需要的不仅仅是一个令牌,例如需要回答某个问题,文本输入也可以包括问题文本。
每项任务的输出都会有所不同。但对于输出结构化的情况,输出将是一个可以转换为 JSON 格式的序列。以下是输出序列符合使用特殊令牌标记字段的开始和结束的示例,该字段可以转换为 JSON 格式。
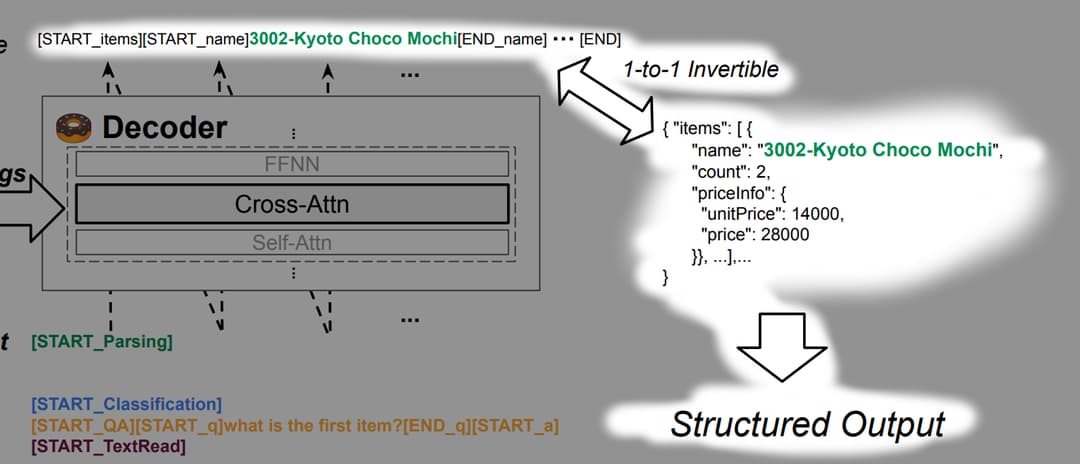
如果输出令牌结构错误,比如 [START_NAME] 存在,但 [END_NAME] 不存在,只需将字段视为丢失即可。
合成文档生成器
之前的工作依赖于使用大规模文档图像数据集进行训练。但当针对现实世界的文档以及需要处理英语以外的其他语言时,便不具备可行性。
因此,作者想出了自己的合成文档生成器来渲染文档图像。它可以有各种背景、布局和文本。作者提到,他们还使用一些图像渲染技术来模仿真实照片。
以下是生成图像的一些示例:

预训练
1.2M文档图像使用 syndog 生成,用于训练集。它使用了维基百科的英语、韩语、日语文本。模型训练时按从左上角到右下角的阅读顺序阅读图像中的所有文本信息。
微调
对每个下游任务进行微调。这项工作将所有下游任务解释为 JSON 预测问题,并执行三种类型的下游任务。
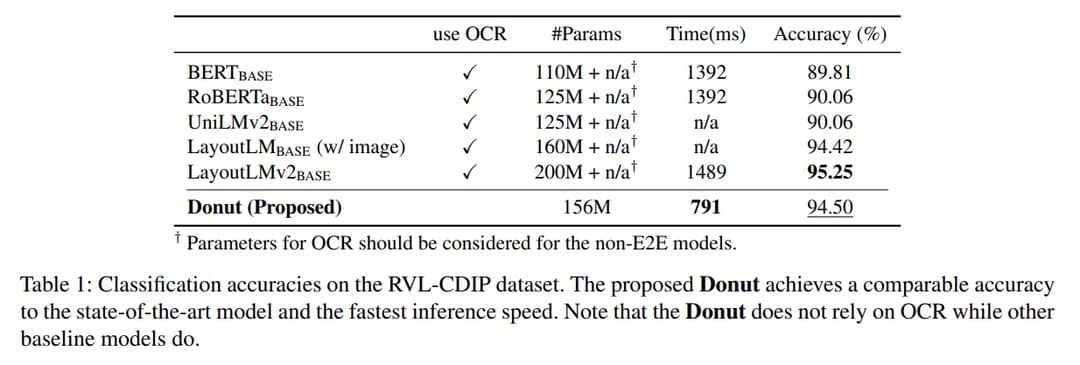
文档分类
显示出与 SOTA 相当的性能
文档解析
评估指标:归一化树编辑距离(nTED)
本任务是从输入文档图像中提取所需的结构化信息,显示出了最佳性能。
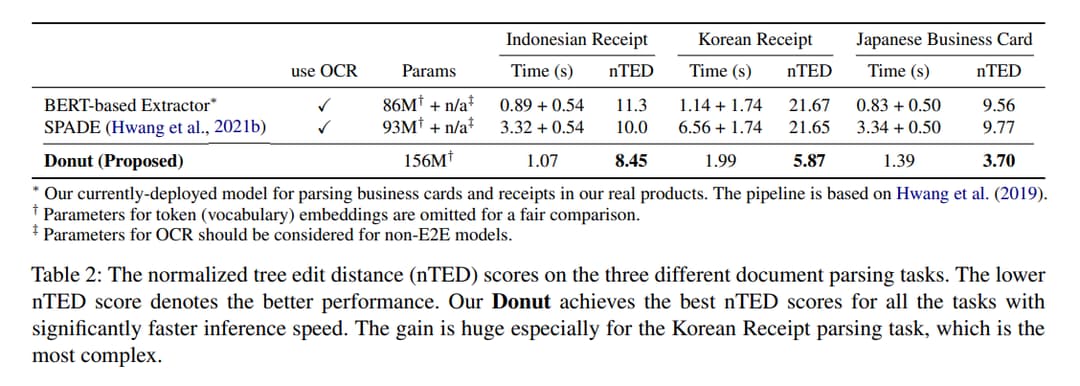
此外,可以通过 attention maps 来定位提取的值,用它们创建边界框也不错。

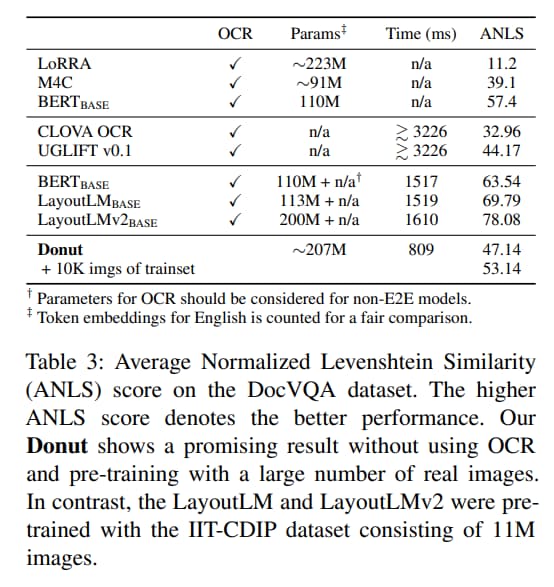
文档 VQA(Visual Question Answering,视觉问题解答)
显示的性能低于 LayoutLMv2。但考虑到 LayoutLMv2 预训练了1100万张真实文档图像大数据集,而本模型使用合成图像,并且只有120万张图像,这种性能差距可以理解。
参考文献
Donut 项目源码:
 clovaai
clovaai