本文整理了4篇最新人工智能(AI)领域论文,包括通过检测计算机发出的电磁波使用卷积神经网络 (CNN) 评估是否存在威胁,谷歌公司基于专家稀疏混合新视觉架构(Vision MoE)原理以及针对未经训练的深度神经网络(DNN)视觉认知能力的研究成果。
摘要: 来自法国计算机科学与随机系统研究所的研究团队创建了一个以树莓派为中心的反恶意软件系统,该系统可以扫描设备中的电磁波来检测恶意软件。
该安全设备使用示波器 (Picoscope 6407) 和连接到 Raspberry Pi 2B 的 H-Field 探头来检测受到攻击的计算机发出的特定电磁波中的异常情况。研究人员称使用了这种技术「获得有关恶意软件类型和身份的准确信息。」然后,检测系统依靠卷积神经网络 (CNN) 来确定收集的数据是否表明存在威胁。
凭借这种技术,研究人员声称他们可以记录被真正恶意软件样本感染的物联网设备的 100000 条测量轨迹,并以高达 99.82% 的准确率预测了三种通用和一种良性恶意软件的类别。
最重要的是,这种检测技术并不需要任何软件,正在被扫描的设备也不需要以任何方式进行操作。因此,攻击方尝试使用混淆技术隐藏恶意代码是不可行的。
团队提出了一个恶意软件的分类框架,该框架以可执行文件作为输入,仅依靠电磁波侧信道信息输出其预测标签。
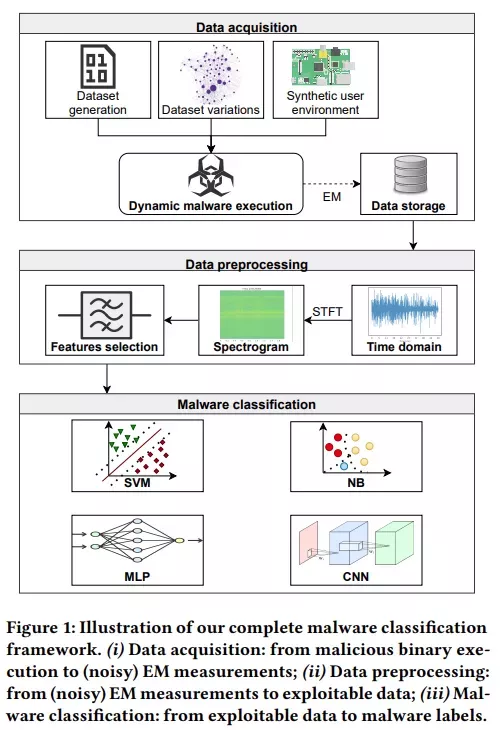
上图展示了该工作流:首先,研究者定义了威胁模型,当恶意软件在目标设备上运行时,收集电磁波发射信息。他们搭建了一个基础设施,能够运行恶意软件与一个现实的用户环境,同时防止感染主机控制器系统。然后,由于采集的数据非常嘈杂,需要进行预处理步骤来隔离相关的信息信号。
最后,使用这个输出,研究者训练了神经网络模型和机器学习算法,以便分类恶意软件类型、二进制文件、混淆方法,并检测一个可执行文件是否打包。
论文链接:
https://hal.archives-ouvertes.fr/hal-03374399/document
摘要: 稀疏门控混合专家网络 (MoE) 在自然语言处理中展示了出色的可扩展性。然而,在计算机视觉中,几乎所有的高性能网络都是密集的,也就是说,每个输入都会转化为参数进行处理。
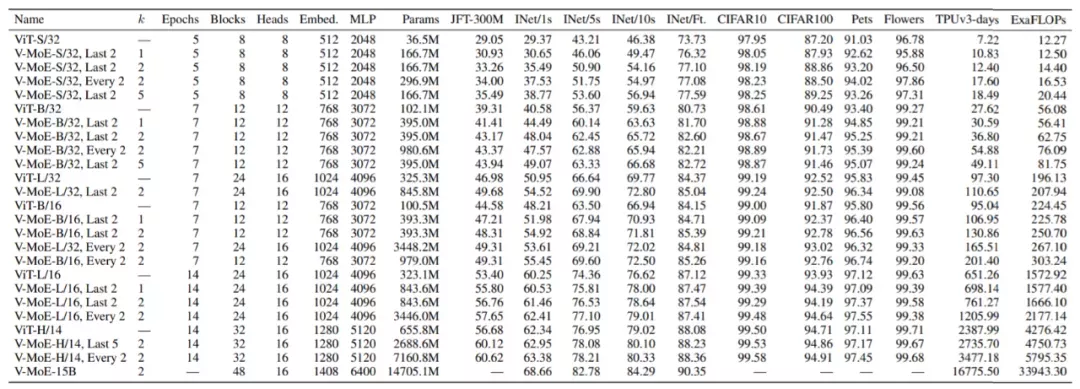
去年 6 月,来自谷歌大脑的研究者提出了 V-MoE(Vision MoE ),这是一种基于专家稀疏混合的新视觉架构。当应用于图像识别时,V-MoE 在推理时只需要一半的计算量,就能达到先进网络性能。
此外,该研究还提出了对路由算法的扩展,该算法可以在整个 batch 中对每个输入的子集进行优先级排序,从而实现自适应图像计算。这允许 V-MoE 在测试时能够权衡性能和平滑计算。最后,该研究展示了 V-MoE 扩展视觉模型的潜力,并训练了一个在 ImageNet 上达到 90.35% 的 150 亿参数模型。
稀疏门控混合专家网络 (MoE) 在自然语言处理中展示了出色的可扩展性。然而,在计算机视觉中,几乎所有的高性能网络都是密集的,也就是说,每个输入都会转化为参数进行处理。去年 6 月,来自谷歌大脑的研究者提出了 V-MoE(Vision MoE ),这是一种基于专家稀疏混合的新视觉架构。当应用于图像识别时,V-MoE 在推理时只需要一半的计算量,就能达到先进网络性能。
此外,该研究还提出了对路由算法的扩展,该算法可以在整个 batch 中对每个输入的子集进行优先级排序,从而实现自适应图像计算。这允许 V-MoE 在测试时能够权衡性能和平滑计算。最后,该研究展示了 V-MoE 扩展视觉模型的潜力,并训练了一个在 ImageNet 上达到 90.35% 的 150 亿参数模型。
ViT 已被证明在迁移学习设置中具有良好的扩展性,在较少的预训练计算下,比 CNN 获得更高的准确率。ViT 将图像处理为一系列 patch,输入图像首先被分成大小相等的 patch,这些 patch 被线性投影到 Transformer 的隐藏层,在位置嵌入后,patch 嵌入(token)由 Transformer 进行处理,该 Transformer 主要由交替的自注意力和 MLP 层组成。MLP 有两个层和一个 GeLU 非线性。
对于 Vision MoE,该研究用 MoE 层替换其中的一个子集,其中每个专家都是一个 MLP,如下图所示:
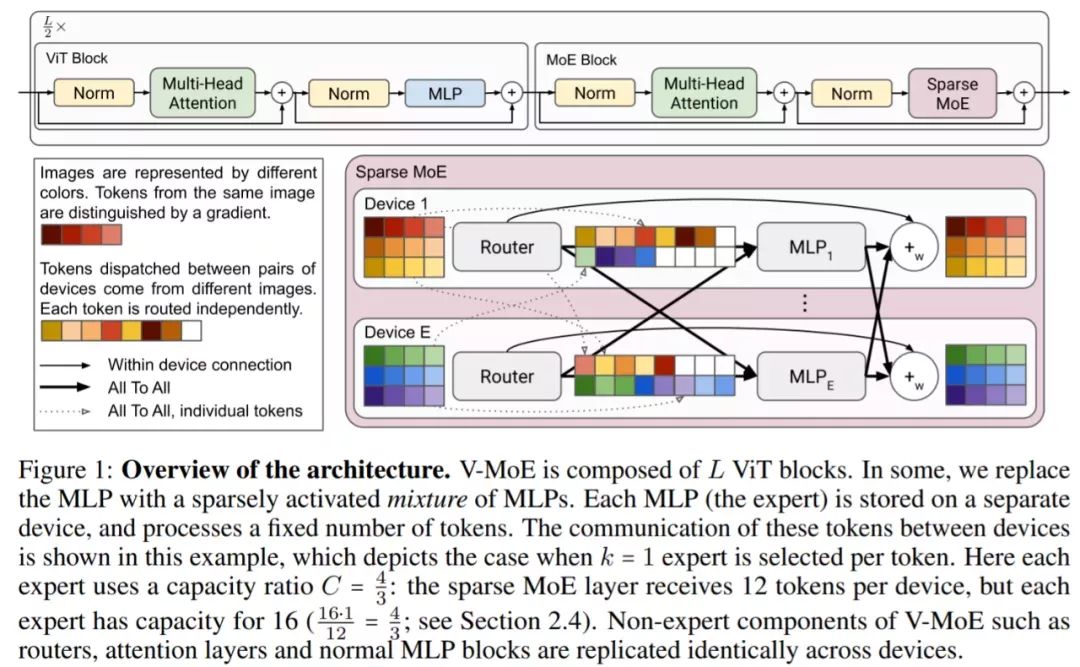
为了大规模扩展视觉模型,该研究将 ViT 架构中的一些密集前馈层 (FFN) 替换为独立 FFN 的稀疏混合(称之为专家)。可学习的路由层为每个独立的 token 选择对应的专家。也就是说,来自同一图像的不同 token 可能会被路由到不同的专家。在总共 E 位专家(E 通常为 32)中,每个 token 最多只能路由到 K(通常为 1 或 2)位专家。这允许扩展模型的大小,同时保持每个 token 计算的恒定。
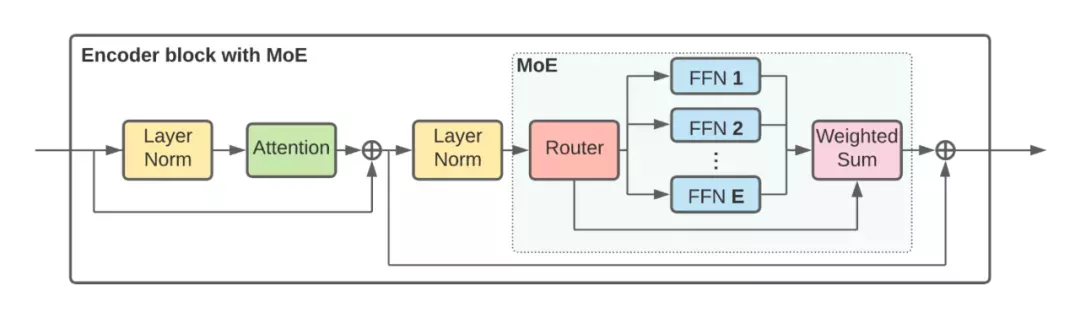
下图更详细地显示了 V-MoE 编码器块的结构。
谷歌前几天已经开源了史上最大视觉模型 V-MoE 的全部代码,参数规模达到了150 亿,项目源码如下:
论文链接:
摘要: 来自 FAIR 、UC 伯克利的研究者重新检查了设计空间并测试了纯 ConvNet 所能达到的极限。研究者逐渐将标准 ResNet「升级(modernize」为视觉 Transformer 的设计,并在此过程中发现了导致性能差异的几个关键组件。
研究者将这一系列纯 ConvNet 模型,命名为 ConvNeXt。ConvNeXt 完全由标准 ConvNet 模块构建,在准确性和可扩展性方面 ConvNeXt 取得了与 Transformer 具有竞争力的结果,达到 87.8% ImageNet top-1 准确率,在 COCO 检测和 ADE20K 分割方面优于 Swin Transformer,同时保持标准 ConvNet 的简单性和有效性。
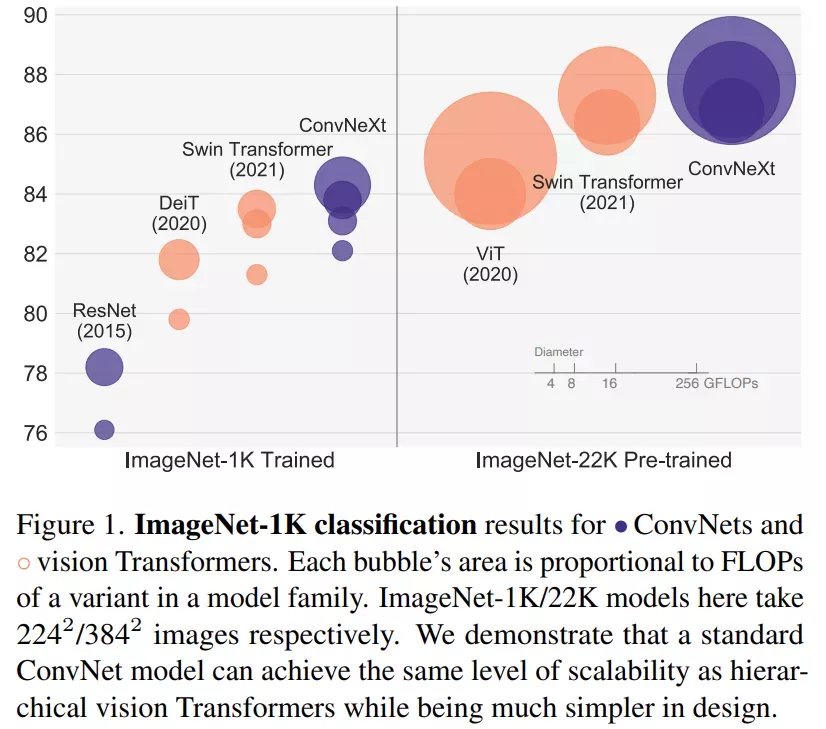
该研究梳理了从 ResNet 到类似于 Transformer 的卷积神经网络的发展轨迹。该研究根据 FLOPs 考虑两种模型大小,一种是 ResNet-50 / Swin-T 机制,其 FLOPs 约为 4.5×10^9,另一种是 ResNet-200 / Swin-B 机制,其 FLOPs 约为 15.0×10^9。为简单起见,该研究使用 ResNet-50 / Swin-T 复杂度模型展示实验结果。
为了探究 Swin Transformer 的设计和标准卷积神经网络的简单性,该研究从 ResNet-50 模型出发,首先使用用于训练视觉 Transformer 的类似训练方法对其进行训练,与原始 ResNet-50 相比的结果表明性能获得了很大的提升,并将改进后的结果作为基线。
然后该研究制定了一系列设计决策,总结为:
- 宏观设计
- ResNeXt
- 反转瓶颈
- 卷积核大小
- 各种逐层微设计
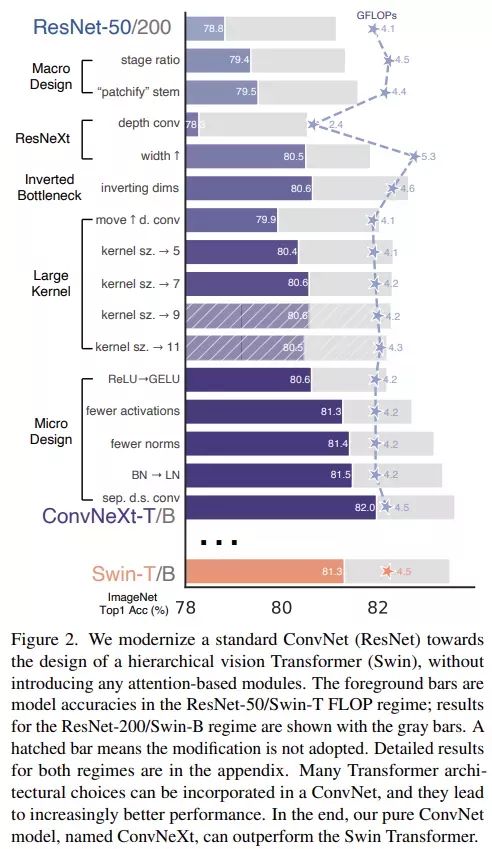
下图展示了「升级网络」每一步的实现过程和结果,所有模型都是在 ImageNet-1K 上进行训练和评估的。由于网络复杂度和最终性能密切相关,因此该研究在探索过程中粗略控制了 FLOPs。
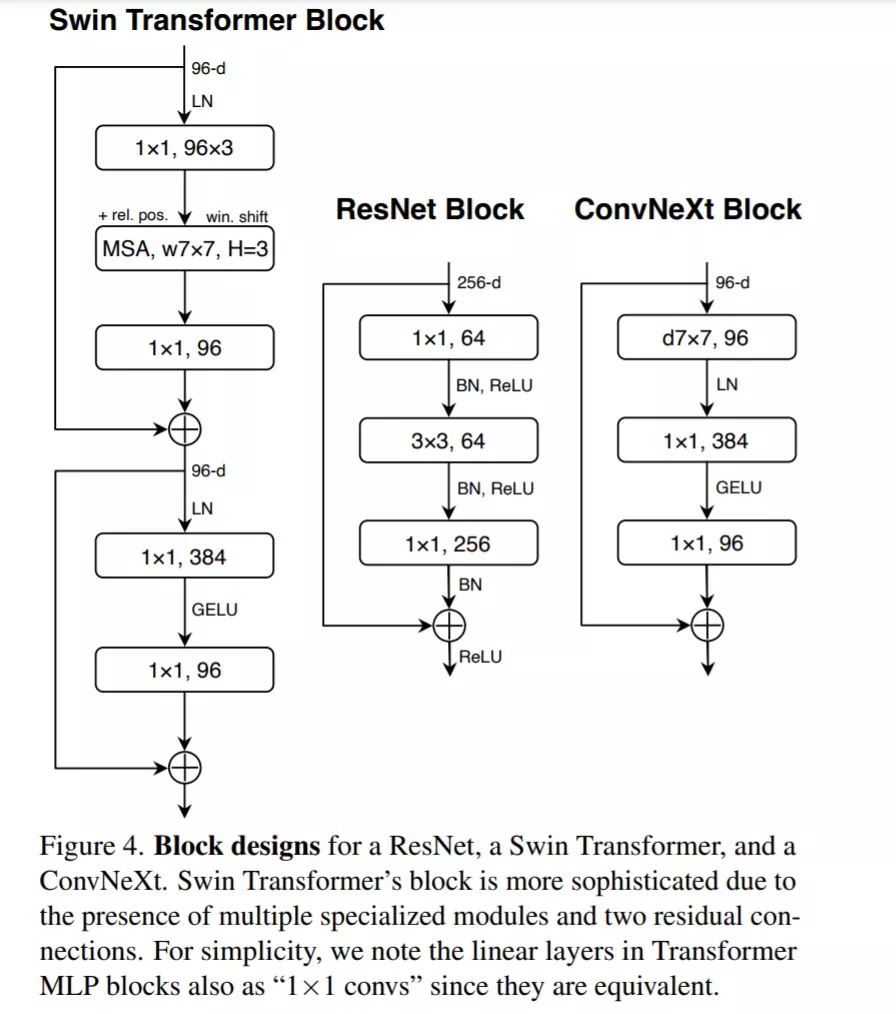
Transformer 中一个重要的设计是创建了反转瓶颈,即 MLP 块的隐藏维度比输入维度宽四倍,如下图所示。
论文链接:
摘要: 近日,韩国科学技术院(KAIST)生物脑工程系教授 Se-Bum Paik 领导的研究小组发现,即使是完全没有经过训练的深度神经网络,也可以产生对面孔图像的视觉选择性。
具体来说,在完全没有学习的情况下,他们在随机初始化的深度神经网络中观察到对面孔图像有选择性的神经元活动,这些活动显示出在生物大脑中观察到的那些特征。这项新研究发表在 12 月份的《自然 · 通讯》杂志上。它为生物和人工神经网络认知功能发展的潜在机制提供了具有启发性的见解,也对我们理解早期大脑功能(感官体验之前)的起源产生了重大影响。
利用捕捉视觉皮层腹侧流(ventral stream)特性的模型神经网络——AlexNet45,研究小组发现,面孔选择性可以在随机初始化的 DNN 的不同条件下稳健地出现。而且,它们的面孔选择性指数(FSI)与那些在大脑中观察到的面孔选择性神经元相当。
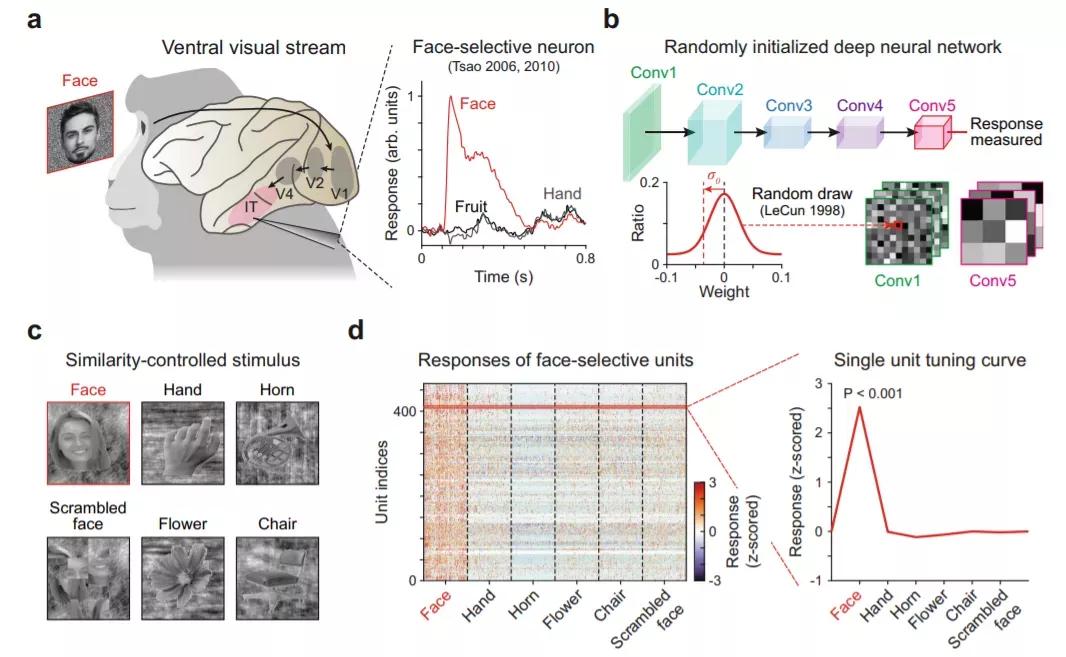

借助反向相关(RC)方法和生成对抗网络获得的优选特征图像(preferred feature image)表明,面孔选择单元对类面孔配置是有选择性的,与没有选择性的单元不同。此外,面孔选择单元使网络能够执行面孔检测。
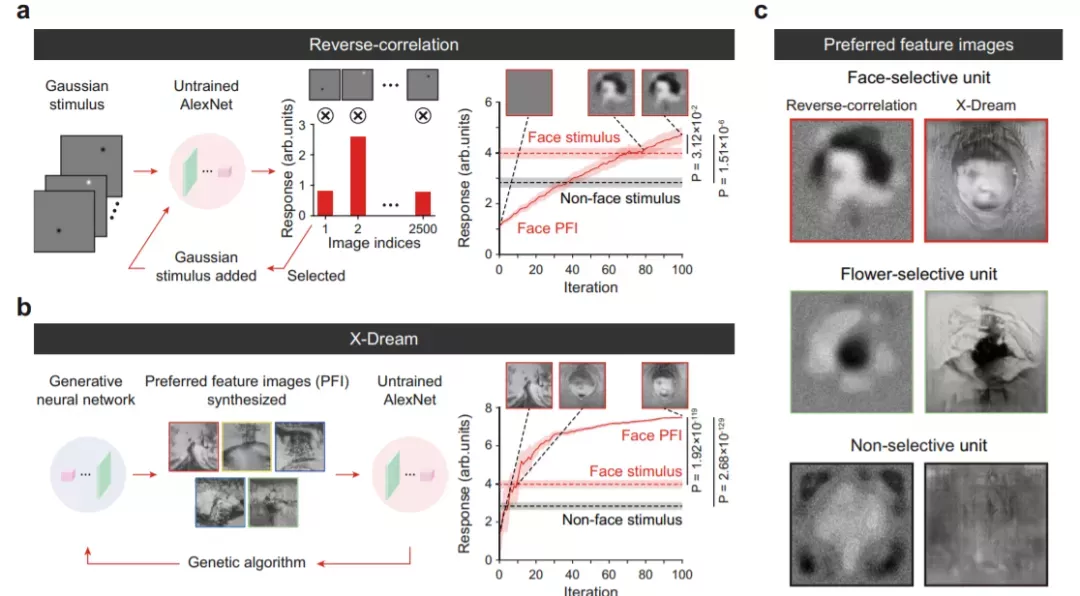
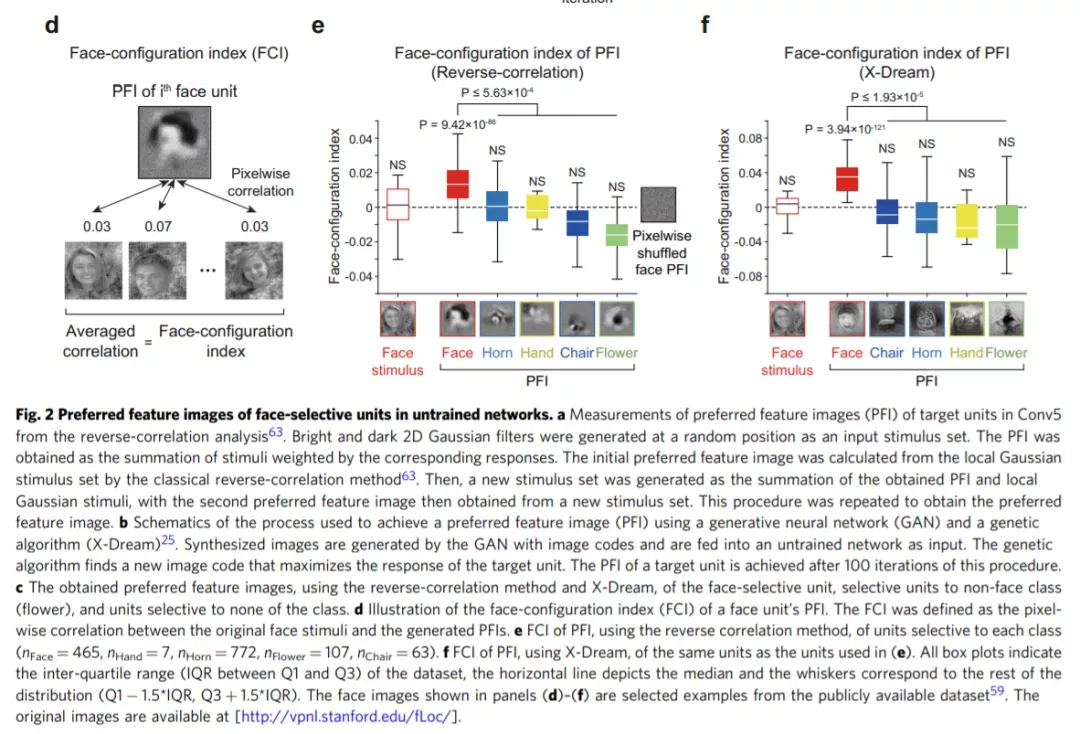
这些结果暗示了一种可能的情况,即在早期未经训练的网络中发展的随机前馈连接可能足以初始化原始的视觉认知功能。
论文链接:
https://www.nature.com/articles/s41467-021-27606-9.pdf