知识爆炸的时代,由于自身阅读和记忆能力的限制,笔者感觉越来越难跟上新知识涌现的步伐。现在,像ChatGPT和Llama这样的大型语言模型为解决这个问题提供了潜在的解决方案,它们提供了一种存储和处理大量信息的方法,我们可以通过提问的方式快速得到问题的答案。
然而,LLM 能回答的问题取决于它们学习的语料库,即使它们大多都有一个庞大的语料库,但这些数据仍然是滞后的。因此,ChatGPT或Bard不能直接向我提供所需的信息。
笔者经常需要阅读大量的专业文献及术语,这个过程消耗了自己太多的精力和时间。导致我即使面对一本很感兴趣的新书,也难以坚持去阅读。
今天小编就来使用 Python 实现一个文档聊天机器人(Document-based ChatBot),它能够即时学习你投喂给它的任何数据(文献、报告、论文等),然后对材料进行总结并且能够基于该资料回答您的问题,最大程度的提升您的阅读、学习及解决问题的能力及效率。类似于 chatpdf.com 的一种实现。
为了实现这个目标,有许多方法可以使用,其中一个是上下文学习(In-context Learning),另一个是模型微调(Fine-tuning)。由于涉及多样化的学习领域,因此我选择使用上下文学习技术。经过研究,我决定基于LlamaIndex以及OpenAI API的文本嵌入(Text Embedding)功能来实现我的文档机器人(Doc Chatbot)。
在本文中,我将详细对基于文档的学习型问答机器人实现方法进行讲解,确保您了解并能够开发自己的文档学习Chatbot。
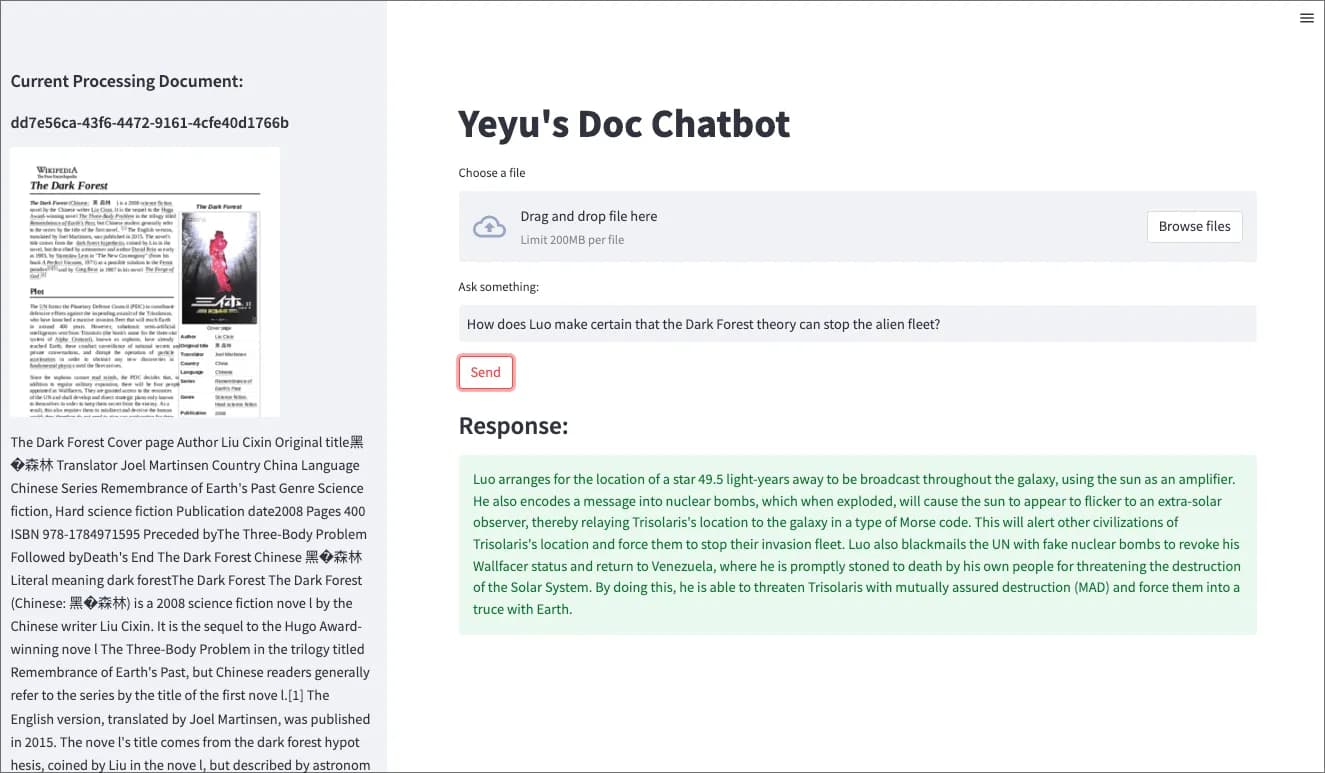
1. 架构图
在本Chatbot中,我们使用llama-index作为基础,并采用Streamlit Web应用程序来提供用户输入提问及回复交互。通过利用llamaIndex工具包内部数据结构和LLM任务管理的优势,我们就可以在调用OpenAI API的时候轻松规避嵌入过程的复杂性以及提示(Prompt)大小限制问题。
2. OpenAI API密钥
LlamaIndex旨在与各种LLM兼容,默认情况下使用OpenAI的text-davinci-003模型和text-embedding-ada-002-v2进行嵌入操作。因此,当我们决定基于OpenAI GPT模型实现 Doc Chatbot 时,应向程序提供我们的OpenAI API密钥。
唯一需要完成的插入密钥的事情是通过环境变量提供它:
import os
os.environ["OPENAI_API_KEY"] = '{my-openai_key}'
3. LlamaIndex
LlamaIndex是一个Python库,提供用户私有数据和大型语言模型之间的中间层接口(中间件)。
LlamaIndex 功能及优势:
数据连接器:LlamaIndex可以连接各种数据源,包括API、PDF、文档和SQL数据库。这使您可以在不进行数据转换的情况下直接使用原始数据与LLM,这也是笔者选择它的关键原因。
- 提示限制:LlamaIndex可以处理提示(Prompt)限制,例如突破 Davinci 模型的4096令牌限制。这确保您的LLM即使在上下文篇幅很大的情况下仍能生成准确的结果,能够节省开发人员管理令牌计算和拆分的时间。
- 索引:LlamaIndex能够在原始语言数据上直接创建索引,使LLM更快、更容易地访问。
- 提示插入:LlamaIndex提供了一种将提示插入到数据中的方法。这意味着您可以管理LLM与数据的交互方式。
- 文本拆分:LlamaIndex可以将文本拆分成较小的块,这可以提高LLM的性能。
- 查询:LlamaIndex提供了查询索引的接口。您将能够从LLM中获取知识参数的输出。
LlamaIndex 提供了一套用于处理 LLM 的综合工具集。这包括数据连接器、索引、提示插入、提示限制、文本拆分和查询。您可以在此处找到完整的文档。
3.1 安装方法
使用以下命令安装 LlamaIndex :
!pip install llama-index
3.2 实现方法
A) 如果您的应用程序只需要一次性加载某些文档文件并查询其内容,那么以下几行 Python 代码就足够了。
第一步 — 加载文档文件
from llama_index import SimpleDirectoryReader
SimpleDirectoryReader = download_loader("SimpleDirectoryReader") loader = SimpleDirectoryReader('./data', recursive=True, exclude_hidden=True) documents = loader.load_data()
SimpleDirectoryReader 是 LlamaIndex 工具集中的文件加载器之一。它支持加载用户提供的文件夹下的多个文件,示例是从子文件夹 ./data/中加载文件。这个神奇的加载器函数可以支持解析诸如 .pdf、.jpg、.png、.docx 等各种文件类型,因此您无需对文档格式进行转换。
第二步 — 构建索引
from llama_index import LLMPredictor, GPTSimpleVectorIndex, PromptHelper, ServiceContext from langchain import OpenAI
...
# 定义 LLM
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003"))
max_input_size = 4096 num_output = 256 max_chunk_overlap = 20 prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index = GPTSimpleVectorIndex.from_documents( documents, service_context=service_context )
在调用此方法时,LlamaIndex 将与您定义的 LLM 互动以构建索引,在这个演示中,LlamaIndex 通过 OpenAI API 调用嵌入方法。
第三步 — 查询索引
有了索引的构建,查询可以通过直接输入而无需上下文数据来简化。
response = index.query("How to use Keytruda in cervical cancer cases?") print(response)
B) 如果您的应用程序具有一些附加功能,并且严重考虑了 API 使用成本,您可以采取以下可选步骤:
步骤1 — 加载各种数据资源
除了 SimpleDirectoryReader 阅读器方法读取本地文档文件外,还有数十种开源阅读器列在 llamahub.ai 上,可以通过 donwload_loader 函数加载。使用方法简单明了。
例如,如果我想从维基百科加载整个《黑暗森林》书的页面,代码将如下所示:
from llama_index import download_loader
WikipediaReader = download_loader("WikipediaReader") loader = WikipediaReader() documents = loader.load_data(pages=['The_Dark_Forest'])
步骤2 — 保存和加载生成的索引
由于索引构建过程花费了 较多的 LLM 使用成本,因此一旦生成索引,就有必要将其存储在本地磁盘中。以后的查询仍然基于相同文档的索引,那么从磁盘加载它是最具成本效益和时间效益的使用方法。
# 保存到磁盘
index.save_to_disk('index.json')
# 从磁盘加载
index = GPTSimpleVectorIndex.load_from_disk('index.json')
步骤3 — 设置响应模式
在调用 index.query() 方法时,考虑到提示成本开销,一个有用的参数 response_mode 可以用来指定响应样式:
- default — 适用于详细的答案
- compact — 适用于成本可能较高的情况
- tree-summarize — 适用于概括性答案
可通过以下代码设定参数:
response = index.query("...", response_mode="default")
4. 网页开发
鉴于便捷性考虑,我们将使用 Streamlit 库来构建我们的文档学习聊天机器人(Doc ChatBot)应用程序。
Streamlit 是一个开源的 Python 库,可以轻松创建交互式的网络应用程序。它旨在供数据科学家和机器学习工程师分享他们的工作。您只需要几行代码便可创建 Streamlit 应用程序,并且只需要一条命令就可以轻松完成部署。
Streamlit 提供了一种可以用来创建交互式应用程序的小组件。这些组件包括按钮、文本框、滑块和图表。您可以从官方文档中找到所有小部件的使用方法:API Reference - Streamlit Docs
一个典型的 Streamlit 网页应用程序代码可以简单如下:
!pip install streamlit import streamlit as st
st.write(""" Hello world! """)
然后只需输入以下命令运行:
!python -m streamlit run demo.py
如果运行成功,用于访问应用的 URL 将被打印出来:
You can now view your Streamlit app in your browser.
Network URL: http://xxx.xxx.xxx.xxx:8501 External URL: http://xxx.xxx.xxx.xxx:8501
5. 文档学习机器人完整实现
为了将 LlamaIndex 和 Streamlit 合并成一个交互式网站,全功能将包括:
- 通过 Streamlit
st.file_uploader()方法创建一个文件上传小部件,接受用户的文档文件上传 - 成功上传后,将文件保存在 ./data/ 文件夹中,并通过 LlamaIndex 生成文档对象,然后调用
st.sidebar()方法在左侧部分打印已经经过转换的内容供用户参考 - 调用
llamaIndex方法针对./data/中的文档文件生成索引对象,并将其存储在网站文件夹./中 - 如果网站根目录
./中已经存在索引文件(index.json) ,一对 Streamlit 小部件st.text_input()和st.button()将被激活,允许用户输入针对当前加载的文档的查询。 - 在后续使用中,将加载现有的索引文件响应用户操作。
完整代码如下:
import os
os.environ["OPENAI_API_KEY"] = '{my_api_key}'
import streamlit as st
from llama_index import download_loader
from llama_index.node_parser import SimpleNodeParser
from llama_index import GPTSimpleVectorIndex
from llama_index import LLMPredictor, GPTSimpleVectorIndex, PromptHelper, ServiceContext
from langchain import OpenAI
doc_path = './data/'
index_file = 'index.json'
if 'response' not in st.session_state:
st.session_state.response = ''
def send_click():
st.session_state.response = index.query(st.session_state.prompt)
index = None
st.title("Yeyu's Doc Chatbot")
sidebar_placeholder = st.sidebar.container()
uploaded_file = st.file_uploader("Choose a file")
if uploaded_file is not None:
doc_files = os.listdir(doc_path)
for doc_file in doc_files:
os.remove(doc_path + doc_file)
bytes_data = uploaded_file.read()
with open(f"{doc_path}{uploaded_file.name}", 'wb') as f:
f.write(bytes_data)
SimpleDirectoryReader = download_loader("SimpleDirectoryReader")
loader = SimpleDirectoryReader(doc_path, recursive=True, exclude_hidden=True)
documents = loader.load_data()
sidebar_placeholder.header('Current Processing Document:')
sidebar_placeholder.subheader(uploaded_file.name)
sidebar_placeholder.write(documents[0].get_text()[:10000]+'...')
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003"))
max_input_size = 4096
num_output = 256
max_chunk_overlap = 20
prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index = GPTSimpleVectorIndex.from_documents(
documents, service_context=service_context
)
index.save_to_disk(index_file)
elif os.path.exists(index_file):
index = GPTSimpleVectorIndex.load_from_disk(index_file)
SimpleDirectoryReader = download_loader("SimpleDirectoryReader")
loader = SimpleDirectoryReader(doc_path, recursive=True, exclude_hidden=True)
documents = loader.load_data()
doc_filename = os.listdir(doc_path)[0]
sidebar_placeholder.header('Current Processing Document:')
sidebar_placeholder.subheader(doc_filename)
sidebar_placeholder.write(documents[0].get_text()[:10000]+'...')
if index != None:
st.text_input("Ask something: ", key='prompt')
st.button("Send", on_click=send_click)
if st.session_state.response:
st.subheader("Response: ")
st.success(st.session_state.response, icon= "🤖")
6. 结论
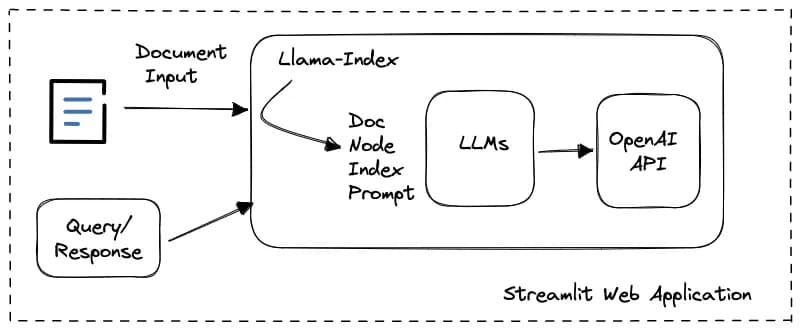
笔者在完成了这个 Doc ChatBot 开发后,自己先体验了一下。我上传书籍《黑暗森林》的维基百科页面给机器人后,提出了一个较难的问题(之前话费了很多时间才获得问题的答案),ChatBot 通过组合几个故事情节完美地回答了这个问题。效果非常好!

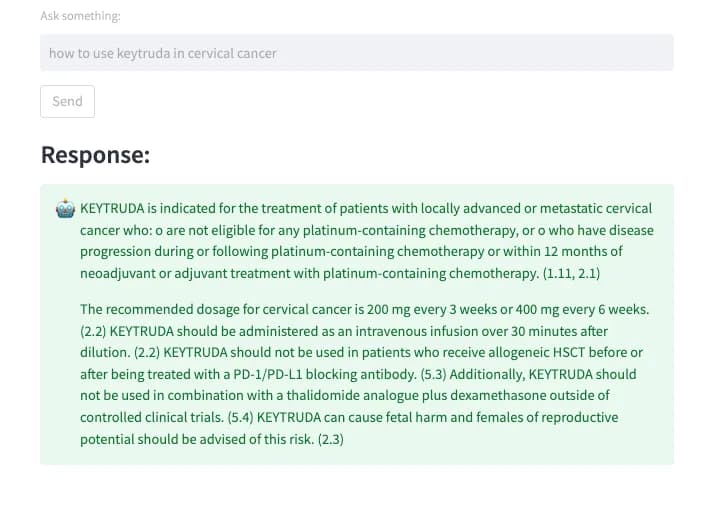
然后,我让 ChatBot 阅读了 Keytruda 说明书(一种用于治疗癌症的人源抗体药物),并询问了其对特定癌症的用法。人工智能机器人给出的回答相当全面,涉及到了多种不同的情况。这种快速学习并获取答案的能力可以节省我大量的时间,并能在我专业知识不足难以解决问题时给我提供准确的信息。
尽管本文中的文档学习机器人实现方法相当简单,但其令人印象深刻的实用性绝对堪当一名合格的人工智能助理。它将为笔者的学习和工作生涯提供强大的支持。
本文的文档学习问答机器人同样支持中文,这取决于投喂的文档所使用的语言。
最后,想实现本文的文档学习机器人,您必须拥有 OpenAI API Key。对于国内的朋友来说,这并不容易。目前,OpenAI 已停止了赠送 API Key 18美元以及5美元的使用额度。想要继续使用 API Key ,您必须具备账户充值能力。
您可以通过这篇文章介绍的方法来对 OpenAI API Key 以及 ChatGPT Plus 进行付费:国内使用信用卡购买 ChatGPT Plus 方法详解