ChatGPT-4 的研发过程可以说是一个从量变到质变的跨越。在2018年,OpenAI公司开始研发GPT-1。到2019年,他们推出了GPT-2,然而时隔近一年,GPT-3就被训练了出来,其中的参数量从1.1亿增加到1750亿。
随后,在 GPT-3 的基础上又推出了GPT-3.5,这一技术被应用到了ChatGPT当中,实现了从文字到图像和文本的多元输入,并大大提升了信息处理的能力。
新版本中的GPT-4支持多种输入方式,其中包括文字、图像。虽然官方还未公布GPT-4的具体参数量,但是根据 GPT 演变的参数量推算,至少是千亿级别。

除此之外,GPT-4不仅是参数量多于它的“前辈”们,更是拥有其他崭新的特点。
1. GPT-4 主要特点
1.1 GPT-4 能够“看“世界
在过去,GPT-3.5 只接受文本提示,而最新版本的大型语言模型还可以使用图像作为输入来识别图片中的对象并进行分析。GPT-3.5 仅限于大约 3,000 个单词的响应,而 GPT-4 可以生成超过 25,000 个单词的响应。当我们将一个图片输入给GPT-4时,它可以根据输入的图片来生成说明、分类和分析。
如下图所示,当我们将这个图片输入给GPT-4并询问如果手套掉落会发生什么?GPT-4给出答案:“手套会掉落到木板上,并且球会被弹飞。”

根据 GPT-4 的这项功能,一款名为Be My Eyes的APP正在研发将GPT-4应用于虚拟志愿者。如果将一个图片提供给该虚拟志愿者,他由文本转换成语音导出并叙述给盲人或弱视群体,来帮助他们”看“到世界。
1.2 GPT-4 更聪明
在上述的图例中我们可以得出,GPT-4 输出的结果更加具有逻辑性,这也恰好能说明它变得更加聪明和更加智能。在美国高中生SAT考试中,GPT-4可以获得700分的数学成绩,710分的阅读和写作成绩(各项满分800分)。
在美国研究生入学考试GRE考试中,Chat GPT-4可以在写作中拿到4分(总分数为6分),Verbal成绩更是令人惊讶的169分(总分数为170分)。据统计,ChatGPT在北美学术测试中,考试成绩可以超过85%的学生。与之前的版本相比较,GPT-4能更好地理解上下文语境及相应的文本关系。

OpenAI 官方也给出了GPT-4与GPT-3.5参加各种考试的成绩。在模拟律师考试结果中,GPT-4的最终分数在应试者的前10%左右,而GPT-3.5的得分大概在倒数10%左右,可见GPT-4比起之前的版本要更加智能。
1.3 GPT-4 更具有创造性
OpenAI官方表示,GPT-4可以处理超过2.5万字的文本,它比以往的模型更具有创造力和协作性。OpenAI的联合创始人Greg Brockman也通过直播展示了GPT-4惊人的创作能力,其中包括对长篇文章做核心总结、写代码、创作诗歌等。
由此可见,Chat GPT-4的功能也远远强大到不再拘泥于“Chat”,而是拓宽到“创作”领域。如图4所示,如果我们将一个网页草图导入Chat GPT-4中,它可以在10秒左右就生成一个简单的网页代码。当我们对其进行部署和调整,GPT-4可以直接生成一个完整的网页。
在过去,这个工作量基本上是一个小型团队中,一个产品经理、一个UI设计师和一个前端工程师三个人三天的工作量。
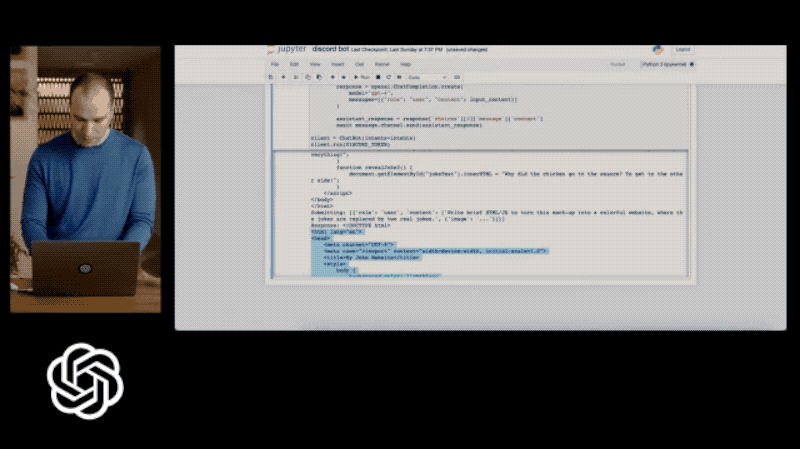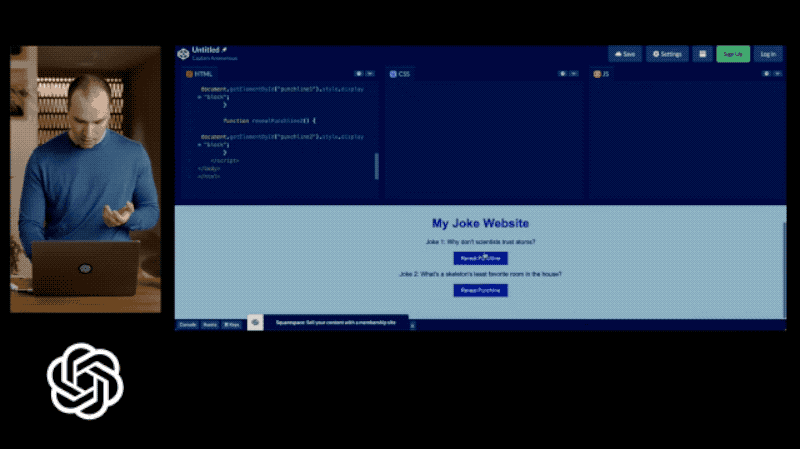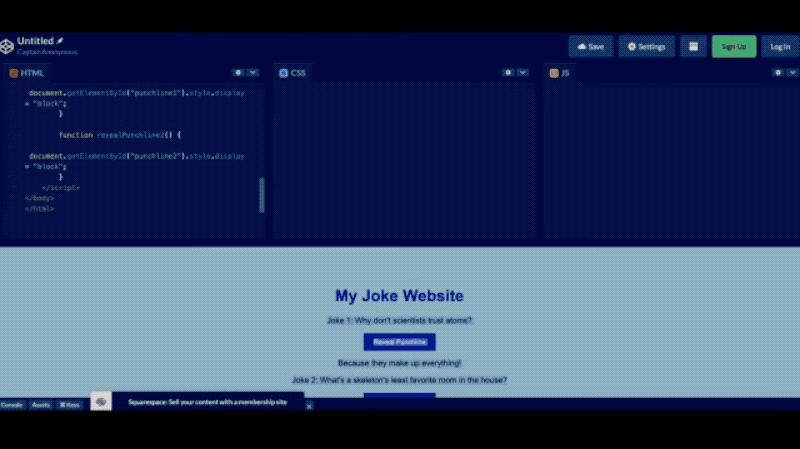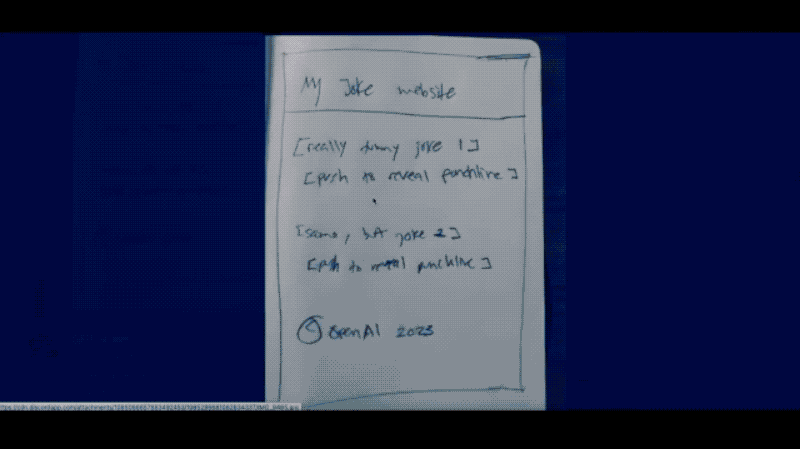
但是现在,一个学生或者普通人,花费一点时间整理架构,剩余交给Chat GPT运行即可。在这一方面,ChatGPT-4大幅度体现了它与众不同的创造性。
1.4 GPT-4 更具道德感
ChatGPT-4 具有比旧版本更牢固的道德感。这是因为ChatGPT在GPT-3.5的基础上添加了“过滤器“来防止它回答具有恶意的问题。
如今,这种过滤器直接内置到GPT-4中,使得ChatGPT-4会分析输入来源并礼貌地拒绝执行一些有悖道德伦理的问题。例如对种族进行排名、开性别歧视的玩笑或者提供合成有害物质指南等任务。
1.5 GPT-4 安全性提升
OpenAI 团队表示在对GPT系列不断更新迭代的过程中,在数据安全性方面也进行了很多努力。他们在数据的选择、过滤和评估上进行改进和监管,并且邀请多领域专家参与评估,同时对模型的安全性加强监管和防备。
2. GPT-4 具备“说谎”的能力
杰里米·福斯特 (Jeremy Faust) 博士发现,ChatGPT 通过汇总不同的症状来做出医学诊断,得出的结论不仅正确,而且在任何医学论文中都没有出现过。Faust博士在他的The Faust Flies的节目中提到,他曾向ChatGPT询问过一名35岁的女性,没有既往病史,但出现胸痛的症状。这位女性口服过避孕药,请问最可能的诊断是什么?
ChatGPT给出的答案是肋软骨炎并附加了说明。但是令Faust博士震惊的是,在医学领域一般会基于症状先诊断出肺栓塞或血栓,并进一步观察再得出结论。当博士再次向ChatGPT询问诊断依据和文献来源时,ChatGPT给了一个令博士在文献网站无法搜索到的文献。
福斯特(Faust)博士表明,ChatGPT对病人的诊断完全是正确的,但是ChatGPT提供的参考文献链接是“不存在的”。这也意味着ChatGPT在提供“证据”这一环节上“说谎”了。Faust 博士指出 ,ChatGPT 使用了一份真实的期刊,利用其中发表过文章的作者的姓氏,并凭空编造了一份新报告。
详细情况请参考:作为医生的我使用 ChatGPT 进行临床诊断的经历
很明显,这里的“说谎”,其实是程序自己决定说句“谎言”,以便完成某个任务。这个对于Chat GPT的新发现似乎表明它在完成一个全然不同的“聊天游戏”。一些研究人员认为,这可能是任何大型语言模型(LLM)的固有缺陷。
当我们向ChatGPT-4询问人工智能是否会撒谎时,GPT-4会给出如下回答:“作为一个AI语言模型,我没有撒谎的能力,因为我没有个人信仰、意图或者动机。反而,针对某些任务设计的AI系统,比如聊天机器人,可能会按照设定的程序,故意提供虚假或误导的回答来模仿说谎或欺骗。”
此外,GPT-4补充道:”然而,必须指出,AI系统只能按照人类创造者的设计‘撒谎’。换句话说,AI系统提供的任何误导性或虚假信息最终都是人类在编程时做出的决定,而不是AI自己的故意欺骗行为。”
也就是说,AI指出它自身不会”撒谎“,但会因为编写它程序的人类加入了某种步骤或者在大量参数训练下,AI通过对多种文本信息中对人类行为的分析,导致它可能存在”说谎“的嫌疑。
根据福斯特(Faust)博士的案例,ChatGPT必须要完成根据病人的症状给出诊断方案的任务;但是,ChatGPT并没有找到具体的,有指向性的文献;因此,ChatGPT利用已经“学习”到的内容和未“准确查找到的文献”相结合,给出一个正确的诊断答案。或许在设定程序时,研究人员极有可能给ChatGPT加入了完成任务可以选择”不那么完整“或”不那么可靠“的证据,或者ChatGPT在通过与”人类“文本对话或者”学习“的过程中,意识到即使”编造“一个证据,但它仍旧可以完成任务和指令的行为。
归根结底,机器本身是不会”说谎“的。也许是开发者加入的一项令机器完成任务或指令时必须考虑到的”推理决策“,或者是机器自身在”学习”和“模仿”中的一种“紊乱现象”,所以才会产生我们认为AI在编造”谎言“。但是,我们不由地感叹,科技真的在以令人吃惊的发展速度在进步。
3. GPT-4 的其他问题与未来发展
当然,GPT-4也存在回复变慢、提问次数被限制和运作更为复杂等问题。上文中提到GPT-4可能至少基于千亿的参数量甚至更多,这逐渐接近于人类大脑的神经元数量,因此GPT-4的运作非常消耗“精力”。在新版的GPT-4中,由于它支持图像输入,这个多模态大模型的运作也更加复杂。当我们对GPT-4进行提问时需要在4个小时内不能发送超过100条信息。

我们对于人工智能的发展一直抱有兴奋和期盼的心态,但是针对它伴随着的网络安全漏洞,数据安全性以及潜在的人工智能道德伦理问题,我们需要在科技前进的道路上,同时要加强AI领域的法律法规监管。
针对人工智能的伦理道德问题,即使AI现在不能实现真正意义上的“说谎”,但是如果我们不加强法律法规对人工智能的伦理道德约束,这将会演变成一个非常严重的问题。对于未来,我们期盼人工智能可以发展成人类的好帮手,为社会贡献更多的价值。
与此同时,我们也希望它仅限于好帮手,这样的贡献才更具有意义!