图像缩放操作是现代计算机视觉中的基础预处理模块。在深度学习革命期间,研究人员忽视了除了常用的可用的最近邻插值、双线性插值和双三次插值等缩放器之外的替代缩放方法的潜力。
我们关注的关键问题是前端缩放器是否会影响深度视觉模型的性能?
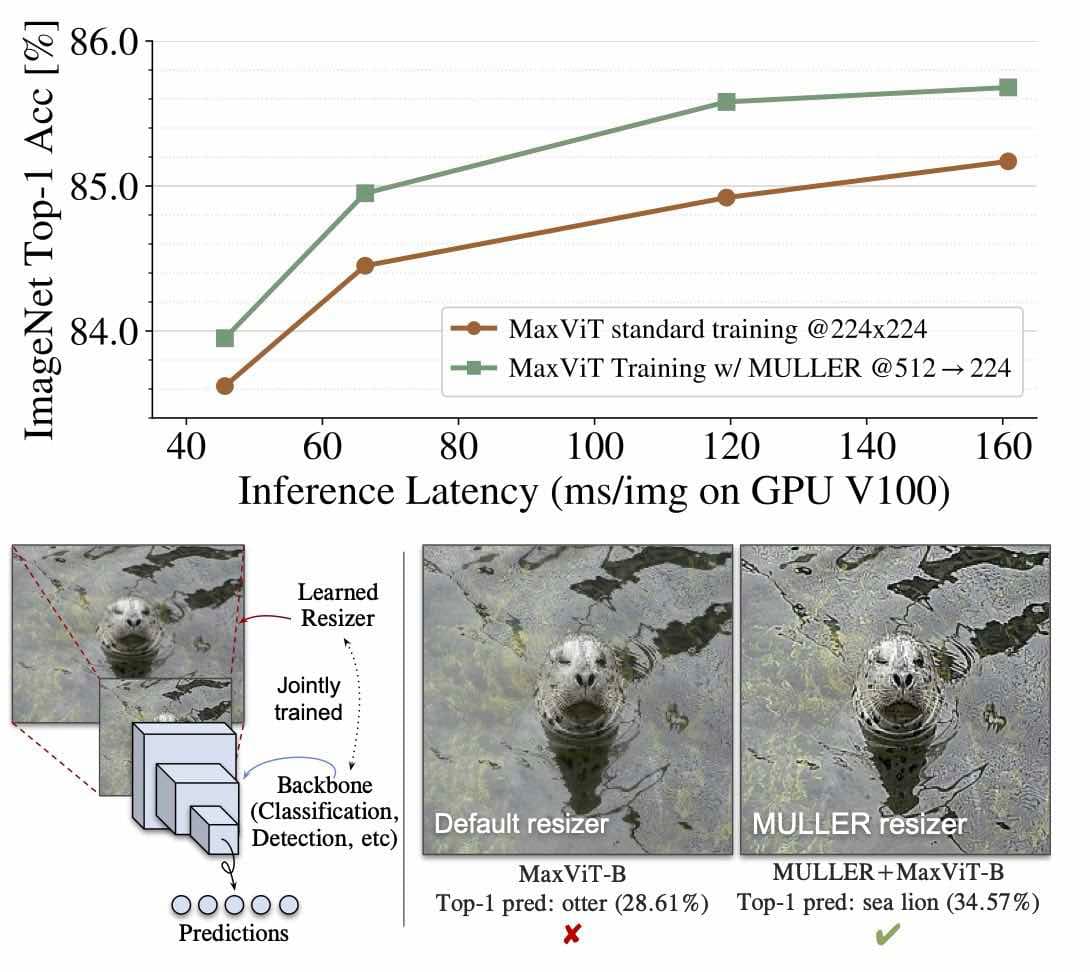
Google MULLER 是一种轻量的、基于多层拉普拉斯分解的图像缩放方法,能有效提高图像识别模型的性能和推理效率。
在本文中,我们介绍的 MULLER 是一种非常轻量级的多层拉普拉斯缩放器,它只有少量可训练参数。MULLER 具有带通特性,它学习增强某些频率子带中的细节,以使下游识别模型受益。
我们证明 MULLER 可以轻松地插入各种训练流程中,并且它有效地提高了底层视觉任务的性能,几乎没有额外的成本。具体来说,我们选择一种最先进的视觉 Transformer MaxViT 作为基线,并表明,如果使用 MULLER 进行训练,MaxViT 的 top-1 准确度提高了0.6%,同时享受 36% 的推理成本节省(与在 ImageNet-1k 上实现类似的 top-1 准确度标准训练方案相比)。
值得注意的是,MULLER的性能也随着模型大小和训练数据大小如 ImageNet-21k 和 JFT 的增加而扩展,并且它广泛适用于多种视觉任务,包括图像分类,目标检测和分割,以及图像质量评估。
论文要点
- 动机:深度学习中,图像缩放方法的前端缩放器会影响深度视觉模型的性能,现有方法受限于常见的可用缩放器,尚未探究其它缩放器的潜力。
- 方法:提出一种基于多层拉普拉斯分解的图像缩放方法 MULLER,能以极低的成本有效地提高深度视觉任务的性能。
- 优势:与现有方法相比,MULLER 具有更高的性能和更高的推理效率;可以轻松地应用于不同的训练流程和多种深度视觉任务中,包括图像分类、目标检测和分割、图像质量评估等。