RNN,递归神经网络(或循环神经网络)已在各领域中展示了其强大能力,尤其是在NLP(自然语言处理)应用中。让机器掌握人类语言中的句法和语义模式并以令人难以置信的准确性复生成文本,着实令人着迷。
也许您是一位狂热的游戏玩家,每天都会尝试各种新游戏。又或许您是一位游戏开发者,需要为玩家自动生成昵称,您都将面临一个问题——浪费脑力去思考使用什么昵称。相信我,多数人为此头疼不已。
笔者将通过本文讲解如何使用 Python 通过 Tensorflow 训练一个递归神经网络,自动为您生成包含意义(非随机字符串)的游戏玩家昵称。
最后,笔者会将此递归神经网络集成到一个 Telegram 机器人,并给出完整项目代码以供下载。
数据源
我们将抓取并使用 这里 的昵称数据作为样本数据来对模型进行训练。
数据抓取及清洗
使用以下代码抓取上述数据源中数据:
from bs4 import BeautifulSoup as bs
import requests
import string
import time
let = list(string.ascii_lowercase)
def get_nicks(Tag):
nicks = []
for line in Tag:
nicks.append(line.text)
return nicks
nicks = []
i = 0
for letter in let:
page = requests.get('http://vnickname.com/letter-' + letter + '.php')
soup = bs(page.content, "html.parser")
results = soup.find_all('li', class_ = 'nicknames-list__item nicknames-list__item_block')
nicks = nicks + get_nicks(results)
time.sleep(0.2)
i = i + 1
print('request {} finished, request status: {}'.format(i,page.status_code) )
与普通单词不同,昵称不需要遵循严格的形态规则,通常是由字母、数字和字符组成的混合体。以下是从数据集中抓取到的昵称的一些示例:
Mr_Apple_Love
Knight In Shining Armor
Aggie
Wagawaga
Angel of Mine
Pickle Head
Emilee
Global Elite
SmallBrain
OmnipotentBeing
Provusci
AMUQI
Boo Bug
M☉neymker
DaR|GoNn.
Landrin
Mnezius
Toots or Tootsie
Luca Jasper
IronMAN77
在清洗数据的过程中,我删除了样本中频次少于10次的Unicode字符,此外,还删除了长度小于5昵称字符串。尽管包含特殊字符或者数字的昵称并不美观,不过人们通常喜欢这么用。因此,RNN也应该尝试学习它们。
以下代码读取数据并生成一个 tensorflow 数据集对象,该对象将以包含 input : target 对的形式封装。
import tensorflow as tf
from keras.utils import pad_sequences, to_categorical
# open the file nicknames.txt
nicks = open('nicknames.txt', encoding = 'utf-8').read()
nicks = nicks.split('\n')
# denotes the end of sequence
new_nicks = [''.join([item, '#']) for item in new_nicks]
# defining vocabulary and character/integer back and forth dictionaries
vocab = ['<pad>'] + sorted(set(' '.join(new_nicks)))
vocab_size = len(vocab)
charId = dict([el, i] for i, el in enumerate(vocab))
idChar = dict([i, el] for i, el in enumerate(vocab))
# defining input and output sequences
inp = [item[:-1] for item in new_nicks]
out = [item[1:] for item in new_nicks]
# transforming input and output character sequences to integer sequences
def char_to_id(name):
name = [*name]
name = [charId[item] for item in name]
return name
inp = list(map(char_to_id, inp))
out = list(map(char_to_id, out))
# padding sequences to a fixed length
inp = pad_sequences(inp, padding = 'post')
out = pad_sequences(out, padding = 'post')
max_seq_len = inp.shape[1]
inp = inp.astype(np.float32)
out = out.astype(np.float32)
# turn input-output pairs into tf Dataset object shuffled and sliced into batches
train_ds = tf.data.Dataset.from_tensor_slices((inp, out)).shuffle( buffer_size = 1000).batch(128)
上述代码中,我使用 # 号表示昵称的结尾,以便生成自定义长度的昵称。在第18行和第19行,我定义了输入和输出序列,其中 n 为昵称长度,输入采用 1 到 n-1 个字符,输出为 2 到 n 个字符。这意味着我将使用“多对多”的RNN架构。
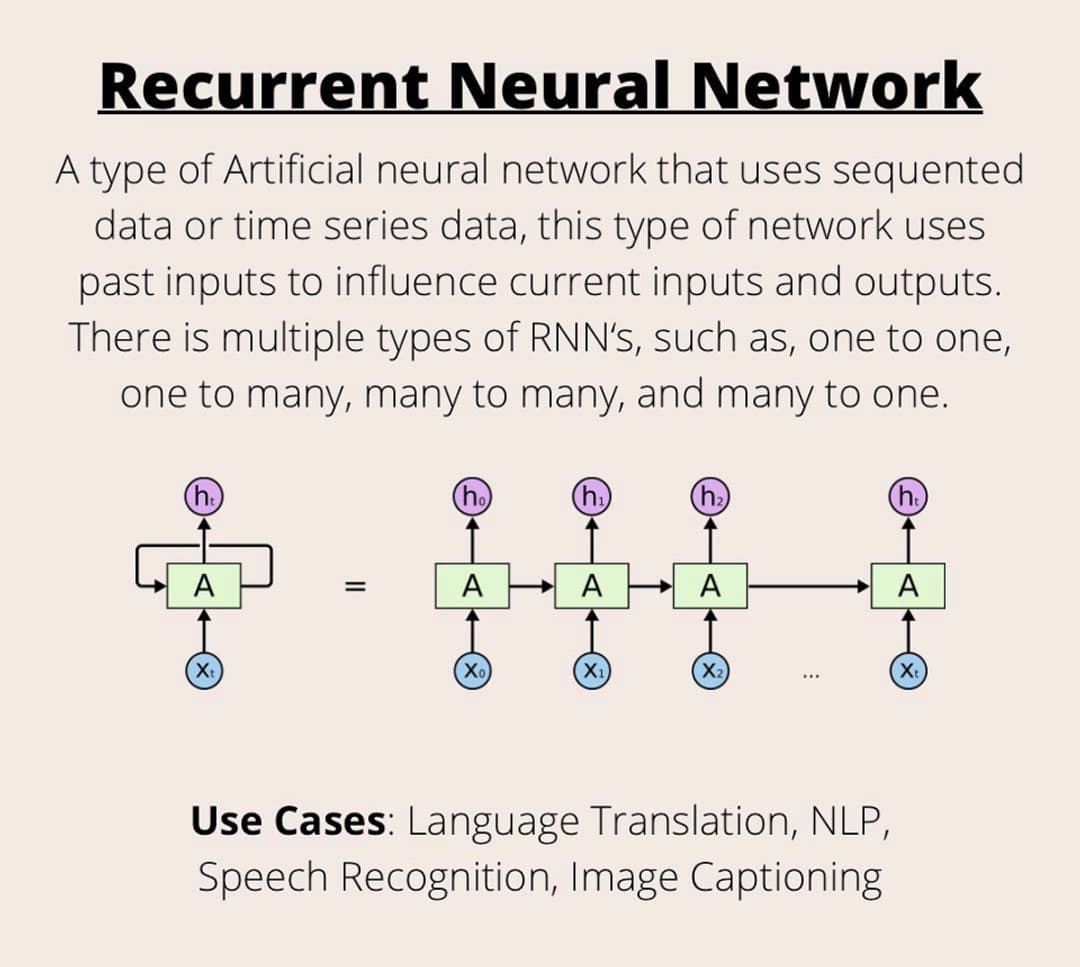
在每个时间步骤中,对于每个传入字符RNN都将预测输出字符。正如此文所述,我之所以采用“多对多”架构而非“多对一”的主要原因在于:首先,我们不需要处理像语句文本那样的长序列。其次,我希望能够通过提供一个字符来生成一个昵称。
第22-27行的功能是将列表 inp 和 out 中的序列转换为由整数组成的二维列表。序列为零填充直至最大长度。部分简单的填充将在接下来的训练环节通过“模糊”处理进行剔除。最后一行将数据集封装为对象用于 model.fit() 函数的输入。
模型构建与训练
使用以下代码片段构建和编译要训练的RNN:
# build the model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, TimeDistributed, Dense, GRU
from keras.callbacks import LambdaCallback
model = Sequential([
Embedding(input_dim=vocab_size, output_dim=50,
mask_zero=True, trainable=True, input_length=max_seq_len,
embeddings_initializer=tf.keras.initializers.random_normal()),
GRU(units=128, return_sequences=True, recurrent_dropout = 0.4),
TimeDistributed(Dense(units=vocab_size))
])
model.compile(optimizer = 'adam', loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
model.summary()
我添加了128个GRU单元,使模型更加灵活,因为该数据集是最不容易学习的数据集之一。然而,有11500多个输入输出对,因此在这里极有可能过度拟合。鉴于我们的目标是从学习到的字符条件分布中抽取新的昵称,而不是优化新字符的预测精度,过拟合应该问题不大。
尽管如此,我们也需要将 recurrent_dropout 参数设置为0.4(该参数控制沿时间步骤传递的内部状态变量部分),用以确保当你使用训练好的模型进行生成时,模型不会只是简单地从数据集中生成昵称。
为了评估模型生成非随机昵称的过程,我们同时将采样函数作为回调函数传递给训练过程。下面的函数每5个历时产生5个样本昵称:
def generate_name(model, start):
chars = list(start)
c = 0
i = 0
while c != '#':
ids = [charId[char] for char in chars]
ids_padded = pad_sequences([ids], value = 0.0, padding = 'post', maxlen = max_seq_len)
probs = tf.nn.softmax(model.predict(ids_padded, verbose = 0))[0][i].numpy()
probs = probs/sum(probs)
d = np.random.choice(vocab_size, p = probs)
if d != 0:
c = idChar[d]
chars.append(c)
i = i + 1
print(''.join(chars).replace('#',''))
def print_on_epoch(epoch,_):
if epoch % 5 == 0:
print('Names generated after epoch {}:\n'.format(epoch))
for i in range(5):
generate_name(model,'#')
name_generator = LambdaCallback(on_epoch_end = print_on_epoch)
model.fit(train_ds, epochs = 300, callbacks=[name_generator], verbose = 1)
参数 start 是起始字符,昵称采样过程会持续直到出现 # 字符。注意,在每个迭代中,我们应该使用与正在生成的字符的索引相对应的概率分布,该索引由 i 跟踪。d 是新生成的整数,应该被映射回一个字符。注意,d = 0 被截断了,因为它对应于字典中的 <pad> 被添加到上文数据清洗部分第12行的字典中。
以下为训练完成后模型生成的一些有趣的名字:
$_Gang
Winguild BoY
Wilf_Of Ear
@ Pump
Rainbow
Red_Z-KY
Badey Maryon
Blondie
Magik
Minnyw MakeMorth
WHOrPing
Wild Maker
XadyBaby-bua
Aracan
Baby ThundDream
不难发现,如果你输入一个大写字母作为昵称开头,模型会生成一个或多或少有些意义的昵称。原因在于多数训练示例从大写字母开始,然后才是小写字母和特殊字符。也就是说,如果你使用特殊字符开头,模型通常产生的昵称质量比较低下(不具有意义),因为它们在数据集中出现的不那么频繁。
笔者已将本文 RNN 模型整合进 Telegram bot,在部署并启动电报机器人后您只需要输入一个首字符,机器人就会为您生成一个游戏玩家昵称。
项目源码: